Hoje em dia, a maior parte das empresas de software produz sistemas com uma arquitetura muito semelhante. Sobretudo no mundo java. Isto não significa que seja uma boa arquitetura. Apenas é a mais comum. E é a mais comum porque acabou virando um meme e as pessoas simplesmente aceitam que seja assim. Então, hoje o objetivo aqui é descrever qual é esta arquitetura e como ele deveria realmente ser para se tornar ainda melhor. Analisaremos também porque essa “ultima milha” não é normalmente feita.
A arquitetura base é a arquitetura client-servidor utilizando HTTP como protocolo. N nodos cliente K nodos servidor de aplicação e H nodos de servidor de banco de dados . Normalmente K = H = 1. Não estou contando aqui com cloud, porque isso ainda não é comum. Nem soluções de balancing porque isso é especifico de cada deploy. No nodo cliente temos um navegador HTTP que interpreta HTML. No nodo Servidor de Aplicação temos a aplicação em si e com quem o cliente se conectar e comunica via HTTP. No nodo de Servidor de Dados temos algum Sistema Gerenciador de Banco de Dados (SGBD).
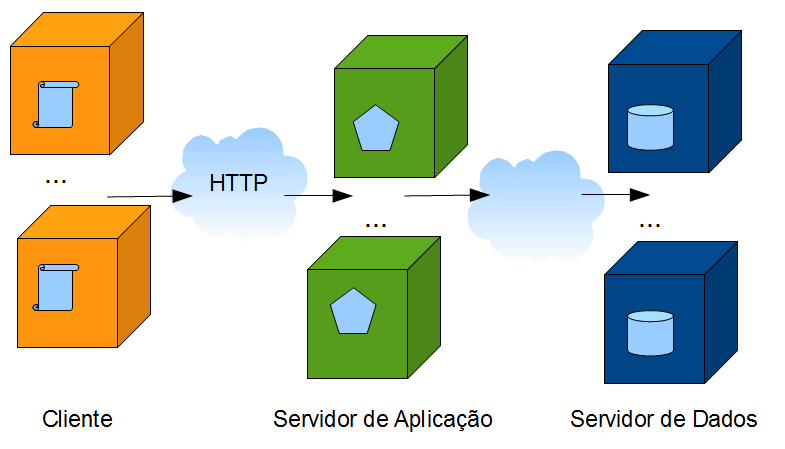
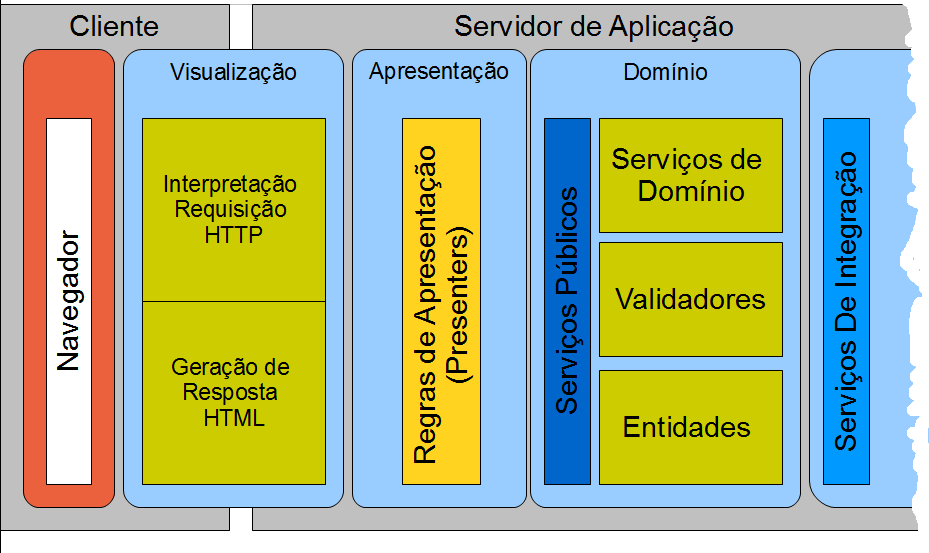
Embora o usuário interaja com navegador no nodo cliente, o básico desta arquitetura é alicerçado no funcionamento padrão do Navegador e dos protocolos HTTP e HTML. Ao informar uma URL ao navegador ele irá incorrer em uma série de mecanismos de localização que irão por fim colocá-lo em comunicação com o Servidor de Aplicação. Nesse ponto a requisição HTTP será interpretada e uma resposta será formulada e devolvida ao navegador. Portanto, em uma arquitetura web a lógica que governa o cliente é dividida em duas partes. Uma parte que vive fisicamente no nodo cliente e é puxada via rede pelo cliente , do servidor, e interpretada no cliente. Esta informação é chamada comumente de “página”. A página pode ser associada um outro conjunto de URLs que precisam ser obtidos simultaneamente para que a página possa ser processada e mostrada ao usuário. Por exemplo, imagens e estilos CSS. Além disso temos também scripts em javascript que permitem controlar e comandar o navegador, especialmente para responder a gestos do usuário como seleções, cliques, drag, drop, e hoje em dia até toque. O sistema então se utiliza desta customização do navegador para entender os gestos do usuário. O gesto do usuário é enviado para o servidor para interpretação. Isto pode ser feito por um comando POST ou GET e pode ser síncrono ou assíncrono (ajax). Temos então toda uma camada de código que lida em criar a interface gráfica dentro do navegador e interpretar os gestos do usuário tanto no navegador como no servidor. Este conjunto de código ocupa p andar de Visualização ( User Interface) e é o primeiro andar no servidor. Ou seja, é a primeira fatia do nodo servidor que comunica com o nodo cliente. Depois que a UI interpretou o gesto do usuário sabemos que o usuário deseja. Por exemplo “salvarOsDadosNaTela” ou “NavegarParaATelaAnterior” ou “FazerLogin” e por ai vai.
Em frameworks action based cada gesto é uma ação que é enviada a um URL de processamento. Internamente esta ação é mapeada para um método em uma classe. O método é onde o programador pode processar uma resposta e depois reenviar o resultado para a mesma URL que fez a chamada, ou outra. Em frameworks baseados em componentes , cada gesto é um evento que algum objeto listenner irá receber (padrão Observer). Esse listenner é eventualmente um método onde o programador pode processar a resposta. Contudo em frameworks baseados em componentes não ha o conceito de URL nem de “página”. Existe o conceito de um componente que representa a tela do navegador e o programador pode interagir com ela como se fosse a tela de um desktop. Todo o processamento do protocolo HTTP, HTML e Ajax é feito pelo framework.
Exemplos de frameworks baseados em acção são o Struts 1 e 2, o Spring MVC , o Grails, o Stripes , o Mentawai e o Vraptor, Exemplos de frameworks baseados em componentes são o JSF , o Wicket, o Vaadin e o ZK.
Conceptualmente todos os gestos são eventos e todos têm que cair em algum método que decidirá o que fazer. Tradicionalmente este método é diretamente o método que o framework provê. Não ha nenhuma outra abstração. Este método imediatamente pode invocar a camada de serviços e realizar tarefas relacionadas à interface gráfica como pintar componentes, escondê-los, desabilitá-los , etc.. Em primeira aproximação isto parece facilitar o trabalho de construção, mas olhando melhor não ha suficiente abstração. O que acontece quando diferentes métodos produzem o mesmo resultado ? Porque não ha uma camada de interpretação dos gestos em si, e apenas dos comandos do protocolo, ha necessidade de replicação de código ou da criação de estruturas de hierarquias de classes para reaproveitar o código e mantê-lo o mais DRY (Don’t repreat yoursefl) possível. Este é um ponto onde as arquiteturas comuns falham. E esta falha custa milhares de reais em todos os projetos e ao longo da vida do produto. Falta uma camada de abstração entre o processamento “cru” dos eventos de visualização e o processamento “alto nível” dos gestos do usuário. O exemplo clássico é ter um botão de “sair” no site. E ao apertá-lo o usuário perde a sessão de autenticação (faz sign off, ou log out). Mas e se o usuário simplesmente navegar para outro site ? Ou se ele simplesmente desligar o navegador ? Não deveria o sistema executar a mesma ação ? Sim, deveria. Mas a forma técnica de saber se o usuário tomou aquelas ações é diferente (normalmente passa por ouvir um evento no navegador com javascript e lançar uma invocação via ajax, ou registrar um listener com web container para saber quando a sessão expirou) . Então o andar de Visualização, pode fazer chegar vários tipos de comandos originados de diferentes lugares, mas todos eles representam a mesma coisa. Então, do ponto de vista do andar seguinte – a Apresentação – eles comandos deveriam ser canalizados para os mesmos métodos nas mesmas classes do andar de apresentação. Este andar é composto por objetos que nada sabem sobre como acontece o processo de comunicação com o usuário. Eles não recebem objetos do frameworks subjacente nem do protocolo ( como HttpRequest ou HttpSession). Este andar é agnóstico assim como todos os outros abaixo dele. Para chegar neste modelo agnóstico é necessário utilizar objetos de transporte entre o andar de cliente e o de apresentação. Padrões como o MVP são muito uteis nesta camada permitindo que todos os comandos do usuário sejam canalizados para os mesmos gestos no objeto Presenter. Existem vários “sabores” do MVP. Uns em que a View é mais ativa e outros onde é mais passiva (ou seja, tem mais ou menos conhecimento sobre as regras dos objetos). Idealmente ela deve ser o mais passiva possível, sem ser completamente estúpida. Ou seja, ela deve automatizar tudo o que for relacionado ao mecanismo do cliente , da visualização em si e da coleta de comandos do usuário, mas não deve interferir com as regras do que deve acontecer. Isto porque, ao colocar as regras no andar de apresentação, ele poderá ser reaproveitado no futuro mesmo que todo andar de cliente seja refeito, remodelado ou até que seja portado para outro tipo de interface gráfica ( Desktop ou Mobile, por exemplo). Isto não é muito difícil, ajuda a organizar o código, ajuda a delimitar responsabilidades e a isolar os os serviços ainda mais para um “core” do sistema que não tem que se preocupar com o que o usuário vê. A longo prazo é um ponto de extensão e de flexibilidade. A longo prazo facilita a manutenção e a modificação do sistema para atender outros tipos de UI e portanto diminui custos e protege o investimento inicial. Sites tendem a mudar constantemente de look and feel para sempre deixarem o usuário com o conceito de “frescura” e de que o site não está abandonado. Sites de e-comerce mudam frequentemente conforme a época do ano ( natal , páscoa, carnaval, etc..) para atender melhor os consumidores. Produtos comerciais que se utilizam da arquitetura web, mesmo que não sejam usando na rede publica, mas apenas na rede da empresa, se beneficiam também pois a usabilidade a experiencia do usuário com o software dependem drasticamente da interface gráfica com ele. O software pode fazer maravilhas internamente, mas se a interface gráfica for pobre, as pessoas simplesmente não o usam. A interface gráfica tem que ser ajustada constantemente para manter o usuário interessado e utilizando o produto. É como a pasta de dentes. Originalmente o produto que realmente faz efeito é cinza. mas quem quer lavar seus dentes com uma pasta cinza ? Então o produto é colorido artificialmente para ficar branco. Apenas a estética é a diferença entre usar e não usar. A estética, a imagem, é também o maior ativo do produto e onde está o maior investimento e risco. Portanto uma arquitetura que permita ter várias visualizações do mesmo beneficio subjacente e que permite comparar a experiencia do usuário com uma e com outra, é uma arquitetura mais econômica.
O andar de Apresentação delega ao andar de Domínio para que este processe as lógicas , as regras , em suma, o propósito do sistema. A forma como a Apresentação faz isso é através de serviços (padrão Service), mais concretamente serviços públicos (padrão Service Façade). A ideia dos serviços públicos é que eles podem ser usados por qualquer camada de apresentação e podem até ser feitos diferentes grupos de serviços para diferentes tipo de apresentação. Contudo estes serviços não realizam nenhuma tarefa ou regra de domínio. Eles simplesmente orquestram chamadas aos verdadeiros serviços do domínio e outros tipos de objetos que existem no domínio a fim de realizar a tarefa prometida à apresentação. Então, por exemplo, um serviço publico pode simplesmente ser uma casca para uma simples pesquisa no banco de dados, ou pode ser a porta de entrada de uma transação complexa onde várias entidades são necessária e chamadas a entrevir. O uso de serviços públicos permite uma grande flexibilidade porque podem reaproveitar vezes sem conta as lógicas mais complexas contidas nos serviços ou nas entidades de domínio. Da mesma forma que uma Visualização pode ser modificada, assim também pode a Apresentação. Como regra geral um elemento disposto em fatias como os andares ,ou as camadas, deve partir do principio que diferentes elementos podem ser colocados acima dele. Então não se trata de poder satisfazer um contrato, mas vários. Mas todos estes contratos têm o mesmo propósito que é , de alguma forma, invocar e utilizar as capacidades da camada de domínio.
Mas o Domínio não vive sozinho e muito frequentemente ele precisa da ajuda de outros serviços, inclusive de outros sistemas, para completar seu propósito. Por outro lado, o Domínio encapsula o estado do sistema em uma forma não trivial e é necessário que esse estado seja persistido de alguma forma, ou todo o esforço do usuário que interage com o sistema seria fútil e em vão. Para isso o Domínio faz uso de Serviços de Integração. Assim como a Apresentação se utiliza dos contratos dos serviços públicos fornecidos pelo Domínio, o Domínio se utiliza de contratos públicos de serviços de outros sistemas. Os dois sistemas mais usuais são o Serviço de Persistência, já mencionado, e o Serviço de Envio de E-mail. Mas outros serviços podem ser necessários conforme o propósito do sistema. Serviços de Cartão de Crédito. Serviços Especializados de Roteamento (Mapas). Serviços de Geo-Localização. E tantos outros. A necessidade do Serviço de Persistência é tão comum que nem pensamos muito nele como um serviço, e mais como uma parte integrante de Domínio. Contudo isto é um erro. É necessário isolar o Modelo de Dominio que são as entidades que formam o negócio (Clientes, Produtos, CarrinhoDeCompras, Estoque, etc..) da sua representação persistente (padrão Memento). Hoje em dias com ferramenta como JPA e Hibernate esta fronteira é muito diluída. Esta diluição é vista como boa e produtiva durante a construção, mas é muitas vezes na realidade um ponto fixo do sistema. O Dominio fica engessado e a seguir o modelo de dados do banco e vice-versa. Ha necessidade de desacoplar estes conceitos e para fazer isso foi sugerido um padrão chamado Domain Store. O Domain Store faz parte do Domínio no sentido que ele conhece e entende o modelo de entidades, mas é capaz de persistir os dados dessas entidades em objetos em um modelo, possivelmente, diferente. Existe então um mapeamento entre o modelo de domínio e o modelo de persistência. O Domain Store é um dos Serviços de Integração mais utilizados hoje. Contudo ainda é muito fundamentado em ferramentas de mercado e poucos se atrevem a criar este serviço de forma mais abstrata. Então, quando um sistema passa de utilizar um SGBD relacional e precisa usar um que não é relacional (NoSQL), ou até os dois em paralelo para guardar informações diferentes, a persistência simplesmente começa a ser uma dor de cabeça.
Se o Dominio é onde estão contidas as regras que tanto trabalho deram para serem levantadas e extraídas dos stakeholders não é prudente desperdiçá-las. Então, da mesma forma que podemos apresentar ao usuários diferentes visualizações das mesmas regras, também queremos utilizar serviços externos e alternar entre eles, com a mesma facilidade. Tudo isto para proteger o investimento que foi feito na produção do domínio. Na produção do core (francês para coração). Temos portanto que o Domínio assenta em um andar de Integração.
A Integração é um andar que provê serviços que não são particulares a um domínio, como persistência, sistema de arquivos, indexação ou e-mail, mas que podem ser utilizados por muitos domínios. Estes serviços são normalmente desenhados de forma agnóstica do domínio e podem servir de fato como substrato para diferentes aplicações, ou seja, diferentes produtos. Por isso estes serviços são muitas vezes chamados de “Serviços de Infraestrutura” , mas é preciso mencionar que os verdadeiros serviços de infraestrutura são aqueles providos pelos outros sistemas e o que temos no nosso servidor são apenas formas de invocar esses serviços, formas de integrar com eles. Por isso é preciso distinguir entre Serviço de Infraestrutura que é realizado pelo outro sistema (por exemplo, um servidor de e-mail é que realmente envia o e-mail e não nós, ou um SGBD é que realmente persiste, e não nós) e Serviços de Integração que são meras representações nossas de como queremos usar esses serviços.
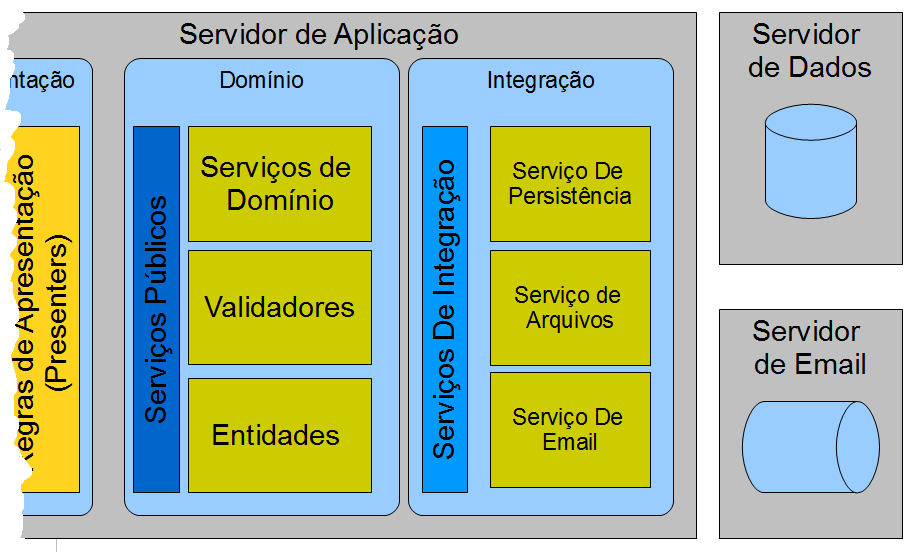
Alguns Serviços de Integração se relacionam a mecanismos dos próprio servidor de aplicação que não estão diretamente relacionados à aplicação como o Serviço de Transação, Serviço de Logging e Serviço de Autenticação. Estes também são serviços reutilizáveis entre aplicações, mas não são providos por outros sistemas, estão embutidos com contexto de execução do servidor de aplicação , ou, como diriam alguns, eles são o Servidor de Aplicação. Por outro lado, quase nunca usamos diretamente os contratos do serviços de infraestrutura. Por exemplo, ao usar o servidor de e-mail, usamos a API Java Mail para a comunicação, mas depois abstraímos essa API numa API própria, mais simples, mais próxima da necessidade do sistema. Isso porque não queremos ficar presos os objetos da API Java Mail para criar nossos e-mails. Eles podem ser criados em qualquer camada de cima, ou até serem entidades do domínio. O mesmo acontece quando usamos a API JDBC para SGBD ou trabalhamos com arquivos usando a API de I/O. Apenas o andar de integração deve saber como essas API “de baixo nível” funcionam e como elas mapeiam para o contratos dos Serviços de Integração. Desta forma quando precisarmos utilizar nosso domínio em uma estrutura de servidor “fisicamente diferente”, mas que contém os mesmos serviços, podemos fazer isso através de utilizar uma camada de integração diferente, mas que expóe os mesmos contratos de serviço que antes. Isto é realmente muito importante para a vida do produto. A tecnologia evolui muito rapidamente. Hoje temos tecnologia de Cloud e servidores elásticos que ha 10 anos não tínhamos. Portar um sistema de uma arquitetura de ha 10 anos para cloud é impossível sem a camada de integração. É necessário reescrever o sistema ou pelo menos parte dele para que ele seja compatível. O aparecimento do Google App Engine (GAE) deixou isto bem claro quando escolheu prover os mesmos serviços de persistência e e-mail de uma forma completamente diferente. Inclusive sem o uso de um banco relacional. Hoje em dia, mesmo com os avanços do GAE ainda é preciso ter certos cuidado, cuidados esses que deveriam ser responsabilidade de um andar de Integração de forma a que nenhuma camada acima tenha que sofrer o impacto da migração de servidor.
Uma boa arquitetura é aquela que poupa seu dinheiro. Não necessariamente no momento da construção, mas principalmente no momento da modificação, da evolução e da adaptação a novas ideias, metodologias, cenários, tecnologias ou ambientes. Seu produto é seu domínio, seu core. E esse é seu ativo (asset) principal. Reescrever outro, significa gastar recursos que já gastou antes. Retrabalho. Cada andar é desenhado com a mesma lógica de proteção. Proteção da Experiencia do Usuário (UX) no andar de Visualização. Proteção de regras de navegação e apresentação no andar de Apresentação. Proteção do core do negócio no andar do Domínio. Proteção de todos os anteriores de mudanças de relacionamento com outros sistemas e ambiente de execução no andar de Integração.
Você pode recordar as aplicações em que trabalhou e comparar com este modelo. Quantas das aplicações que lembra tinham andar de Apresentação separado do de Visualização ? Quantas usavam Serviços Públicos para não expor os serviços de Domínio ? Quantas isolavam interações com outros sistemas usando serviços especiais de integração ? Quantas realmente poderiam modificar seu cliente visual , não apenas em look and feel mas também em tecnologia ( não apenas mudar o layout web ,mas mudar de web para desktop) ? Quantas implementavam um cliente HTTP/HTML pobre e quantas foram evoluídas para um cliente mais rico usando Ajax ? Quantas fizeram isso preservando o cliente original ?
Quanto dinheiro, tempo e esforço foi desperdiçado ao longo da vida dessas aplicações ?
Vivemos numa era de crise de valores. Hoje é mais aceitável fazer rápido do que fazer bem. Todos olham quanto custa criar o sistema, mas pouco olham quanto custa manter o sistema. E se alguém faz um sistema em 2 ou 3 anos, é para ele ser usados por 20 ou 30. Logo, o custo está no longo prazo e não no curto. Mas infelizmente vivemos na era do “projeto” e não do “produto”. Pelo menos no Brasil. Os clientes querem um produto, mas o que vendemos para eles é um Projeto. E projetos ha muitos. Produto ha só um. Alguns clientes aprendem na prática e duras custas quando são enganados por aquela Fábrica de Software que fez um contrato para ‘um Projeto de Software” e falhou. E o cliente contrata uma, duas, três Fábricas de Software e sai sempre de mãos vazias. Alguns clientes se contentam até com apenas um contrato para “a especificação de um Projeto de Software”. Isso é como você comprar a planta da casa sem nenhum compromisso que algum dia aquela casa será construída. O problema disso é que essa planta tem validade. Uma validade imposta pelo mercado, a tecnologia, e as próprias ideias do cliente que evoluem. O que era ontem, não será amanhã. Isto é a única coisa que podemos ter a certeza. E a nossa arquitetura deve lidar com esta realidade.
E não se confunda o que estou dizendo com alguma tentativa de dizer que a onda ágil está errada e que devemos voltar às especificações de uml. Nada disso. Bem pelo contrário. Mas também não se confunda acreditando que é possível construir um sistema que dure no tempo e proteja seu dinheiro , sem ver e entender “the big picture” e os erros cometidos ao longo da historia. Design você pode evoluir como quem muda a cor das paredes ou mudas os cortinados e os abajures. Mas arquitetura não evolui. O banheiro sempre será onde é. A cozinha sempre será onde existe calor e água para cozinhar. Mudar essas coisas não é evoluir a arquitetura. É fazer outra arquitetura. Mas destruir para construir de volta é jogar dinheiro fora. Em software parece que não é tão caro, porque estamos só mexendo com bits , tem virtualmente custo zero. Mas o que custa não é partir pedra ou mudar bits. O que custa é partir pedra da forma errada ou mudar os bits da forma errada. E qual é a forma errada ? Aquela que não perdura. Stonehenge, as Pirâmides, a Muralha da China, e tantas outras construções são consideradas boa arquitetura porque perduraram. Ninguém lembra dos edifícios obliterados pelo tempo.
Arquitetura de software não tem assim tantas configurações possiveis. Todas são repetições ou aglomerados de 3 tipos básicos de padrão : cliente-servidor, peer-to-peer (P2P) e publish-subscribe (Mensageria). Só isso. De longe a mais usada é Cliente-Servidor, mas hoje em dia o mais comum é termos um hibrido entre as três. Pegue uma aplicação JEE comum. Temos Cliente-Servidor, claro, mas temos mensageira (JMS, Java Mail, ESB) e P2P (cluster, cloud, NoSQL). Não ha como driblar este fato. Os ativos da sua empresa ou os do seu cliente vão estar embutidos na arquitetura que escolher e nas decisões que tomar. Quanto menos decisões tomar, melhor. Ou seja, quanto menos coisas tiver que restringir a pontos fixos melhor. E isso significa abstrair o que pode mudar em módulos. E esses módulos em camadas. E as camadas em andares. E os andares em nodos.
Criar uma aplicação com a arquitetura padrão que descrevi tem o mesmo custo que criá-la sem. Uma camada a mais é mais uma forma de organização do código do que uma questão de ter mais código ou menos. Logo, o esforço não é braçal, mas intelectual. E o trabalho intelectual sempre tem a mesma velocidade. Logo, não é o custo que impede as empresas ou os desenvolvedores de criarem arquiteturas robustas e sim a sua falta de conhecimento ou a sua falta de comprometimento com o retorno financeiro da aplicação que estão construindo.
Espero que depois que leu isto, veja suas aplicações de outra forma e entenda porque aquele sistema Z teve que ser redesenhado 2 anos depois de ter sido entregue, ou simplesmente foi jogado fora e um outro foi feito.
Fala Sérgio,
Eis um pensamento “fora da caixa”. Sua abordagem me fez pensar e pensar sobre o que significa o termo “Arquitetura” e como ela está sendo vendida atualmente. Tudo o que disse é totalmente verdade nos dias de hoje e assim persistirá por mais um longo tempo.
Acredito que até uma arquitetura orientada a serviços, que foge desta receita de bolo por decompor tudo em serviço, diminuindo o DRY; ainda está desenhada com este mesmo cerne descrito por você e assim, fatalmente está a mercê de retrabalhos e altos acoplamentos dentro de cada módulo do “produto”, concorda?
SOA é apenas uma forma de organizar o andar de domínio. Deveria ser uma forma de organizar os serviços públicos e proteger os serviços de domínio se aplicações diferentes e de certa forma ajudar na integração também, mas realmente – concordo – os serviços acabam mais vezes que menos sendo altamente acoplados a quem os chama. E muitas vezes o próprio serviço de dominio é exposto em vez de uma façade. Isto era assim no EJB, é assim no ESB. As ideias ainda são as mesmas. É dificil para as pessoas entenderem o que é core, e como isolá-lo. E isso advém de que elas não foram ensinadas a isolá-lo, nem lhes foi mostrado porque isso é vantajoso. O EJB 2 era feito com esse objetivo, e as pessoas achavam muito ruim. Porquê ? Porque o usavam da forma errada. Tudo era remoto, em vez de algumas coisas serem locais (core) e algumas coisas serem remotas (publicas, façade). Hoje em dia nem tem mais essa distinção. Tudo é local, e é ainda mais dificil destinguir o que é serviço de dominio do que é serviço de façade. E ai vc joga o ESB no meio e ai sim tudo liga com tudo e vira um anti-layer. Uma pena realmente.
Muito interessante essa arquitetura apresentada. Estou com uma dúvida. Pensando no seguinte requisito: antes de cadastrar um usuário no sistema devo verificar seu CPF, em algum serviço de terceiros para essa finalidade. Esse serviço pode ser chamado dentro de um Domain Service? Ou deveria ficar num Application Service?
Nesse caso em especial ficaria dentro de um Validador que depois seria usado pelos serviços de domínio onde necessário.Isto porque se trata de uma regra de validação. O fato de ser um terceiro a validar é um detalhe. Do ponto de vista da app é o validador que está fazendo esse trabalho.
O serviço de validação invocado, neste caso, seria parte do andar de integração. Ele mesmo seria um serviço de integração.
Outros serviços de integração – que não sejam de validação – podem ser chamados diretamente por outros serviços, sejam eles de integração , domínio, ou façades. Não sei o que quer dizer com “Application Service”.
Application Service, seria a camada de serviços que orquestram os Domain Services, para quando haja alguma funcionalidade que precise chamar vários domain services em uma ordem específica.
Minhas principais dúvidas surgem por normalmente trabalhei meus domain services, chamando repositorios, que representam onde armazeno meus dados, normalmente um banco de dados.
Mas nunca trabalhei com funcionalidades mais avançadas, onde por exemplo dentro de um domain services alem de chamar meus repositorios, chamasse também outros serviços da infra, como webservice de terceiros. Nem sei se é correto fazer essa mistura.
Para tentar explicar melhor, por exemplo num domain service UserService, tenho um método registerUser(User user).
Dentro desse método, faço algumas validações do user, depois chamo o repositório para adicionar no banco e por último envio um email para esse novo user.
Esse passo de enviar email, utilizando um emailService, dentro do método registerUser está correto?
Ou somente deveria trabalhar no domain services com coisas relacionadas aos repositorios de dados.
Está correto. Dentro da camada de domínio um serviço e um repositório valem o mesmo. Ou seja, um serviço pode chamar outro serviço ou pode chamar um repositório.
Um serviço pode chamar outro serviço do domínio ou um serviço de integração. O EmailService seria um serviço de integração.
O primeiro serviço chamado ( que vc chama de serviço de aplicação) é responsável pela fronteira da transação. Então, no seu exemplo, enviar o email e registrar o usuário no banco é uma transação só. Não queremos registrar sem enviar o email e vice-versa. Dentro do dominio não ha essa precoupação pois o foco é com o negocio e não com a infraestrutrua tecnologico. Mas todos são serviços.
O domain service não se restringe a conversar com os repositórios, isso seriam os serviços crud muito básicos. Mas os serviços de domain de processo que são aqueles que realmente fazem alguma coisa (embora possa parecer apenas um crud, mas sempre tem mais alguma coisa tipo o cadastro de pedido que dispara o envio da mercadoria) são mais complexo. O que não deve ser feito é criar um serviço de domínio que simplesmente é uma casca do repositório. Isso não tem sentido.
Os únicos serviços que podem ser uma casca são os de aplicação.
Acho que entendi. Então em meu domain service, UserService, dentro do método registerUser posso chamar tranquilamente meu repositorio de user e meu serviço de email, sem medo de estar fazendo gambiarra.
Essas dúvidas surgem muito também porque normalmente eu fazia o paralelo de domain service com minhas antigas stored procedures que tinham as regras de negocio, porem somente referente a dados, nada de envio de email, etc.
Gostei, muito do artigo.
Já li umas 4 vezes como referência.
Mas uma dúvida, qual camada ficaria responsável pela formatação dos valores inseridos pelo usuário para armazenamento?
Exemplo simples, nome e outros dados em letra maiuscula, tamanho maximo de strings, formatação de ceps, cnpjs e outros documentos e por ae vai….
Eu geralmente faço esse tratamento na view, com java script e após na action que recebe esses dados.
Como o nome indica “formatação” é uma coisa puramente visual. Portanto, na camada de visualização.
Os formatadores são objetos que convertem de um objeto de classe X para String e vice-versa. Os classicos formatadores de data, cnpj, etc…
O Truque é nunca transitar o dado formatado. A Visualização sempre irá converter para o objeto do tipo X e é esse dado que trafega no resto do sistema. a String formatada é “for user eyes only”
Coisas como letra maiúscula , para mim pessoalmente, eu condeno. Nao ha razão hoje em dia para isso. Não estamos no clipper e java suporta UTF-16. Se for mesmo necessário, não é uma responsabilidade da visualização porque vc está modificando os dados (está destruindo informação na realidade). Então tem que ser em algum ponto do dominio ou da camada de façade. Este ponto é bem ambiguo. Eu precisei fazer isto uma vez e acabei precisando que várias camadas fossem conscientes do assunto. Não é legal. Mas não é legal porque o requisitos em si é furado.
Javascript é legal para controlar em realtime e formatar em realtime , mas é sempre bom ter um filtro ou um interceptor ou qq coisa que faça o meio campo. Uma coisa que dá muito problema é datas. Se o usuário colocar uma data que não existe ( 30/2/2013) o que o formatador faz ? se formatar para null, o validador irá acusar que o usuario não colocou o campo, o que é mentira. Se ele tentar converter para Date vai dar erro porque não existe. Então, às vezes é melhor trabalhar com objetos de view, e ter uma validação desses objetos na visualização exatamente por causa das formatações. Se entrar i18n , então, fica ainda mais complexo. E tudo isso é coisa da visualização. Depois que está “visivelmente válido” podemos converter para os objetos reais como Date. Aqui já sabemos que não ter problema de formato. Resta saber se ter problema de regra ( tipo a data é fora de um range de negocio qualquer… ). Parece que estamos validando a mesma coisa 2 vezes mas não. Na primeira estamos validando o input “cru” propriamente dito, e na segunda a regra de negocio. Então é bom que além do javascript sempre haja validação do lado do server, tanto no andar de visualização como na de serviços. É que no futuro esses serviços podem ser uados por outro andar de visualização diferente e quem garante que elas verificam essas coisas ? O serviço tem que se proteger. Afinal ele tem que fazer cumprir o seu contrato.
Olá Sergio,
Você tem algum projeto com o código-fonte para vermos que use essa arqutitetura (ou o mais próximo dela)?
Infelizmente, neste caso, porque eu trabalho em aplicações para outros, eu não detenho o código de nenhuma das aplicações que já fiz, então infelizmente não ha nenhuma que pudesse apresentam o código fonte. Por outro lado, não sei se olhar o código fonte ajuda se os conceitos não estiverem bem assentes.
Tem alguma dúvida especifica ?
Obrigado por responder. Ok, não tem problema.
Eu fiquei em dúvida na seção de apresentação (presenters).
Vou especificar: tenho dúvida de como ficaria o código dessa seção (realmente é uma ótima ideia!), como seriam os objetos e as funções.
Olá Sergio grande artigo,na verdade grande blog.
tenho uma arquitetura bem parecida com o proposto aqui em outro post do blog http://www.javabuilding.com/architecture/arquitetura-com-domainstore-repositorio-e-query-object.html
no entanto tenho algumas dúvidas em relação à minha arquitetura,por exemplo tenho meu repositorio:
@Stateless
public class ContratoRepository extends AbstractRepository{
@PersistenceContetx
private EntityManagem em;
public void save(Contrato c){em.persist(c);}
public Contrato find(Integer id){return em.find(Contrato.class,id)}
}
tenho minha classe Service, que chama meu repositório e outros serviços e outros repositórios,como esse serviço vai ser acessado por 2 sistemas diferentes onde cada sistema só poderá fazer algumas operações esse serviço implementa 2 interfaces,vamos supor
@Local
public interface ContratoService{
public Contrato find(Integer id);
}
@Local
public interface ContratoAdmService{
public Contrato find(Integer id);
public void save(Contrato c);
}
@Stateles
public class ContratoService implements ContratoService,ContratoAdmService{
@EJB
private ContratoRepository repository;
@Inject
private EmailService emailService;
public void save(Contrato c){
Validator.validate(c);
repository.save(c);
emailService.send();
}
}
no meu controller do ZK (MVVM) eu chamo meu repositório para operações de escrita e meus services para operações onde há mudanças de estado
public class ContratoVM{
@EJB
private ContratoAdmService contratoService;
@EJB
private ContratoRepository repository;
private Contrato contrato;
@Command
@NotifyChange(“contrato”)
public void save(){
contratoService.save(contrato);
}
@Command
@NotifyChange(“contrato”)
public void find(@BindingParam(“id”) Integer id){
this.contrato = repository.find(id);
}
}
Você considera correto eu ter um entitymanager agindo como o domainstore dentro do meu repositório ou deveria isolar isso em outra camada?
posso ter problemas injetando esse monte de @EJB?
no geral esta arquitetura está boa?
Sim, a sua arquitetura está boa. Acho que vc quiz dizer que chamava o repository em operações de leitura (em vez de escrita).
Sendo que vc está usando um servidor EE não ha problema em usar as anotações dele nem o EntityManager dele. Sendo que está escondido no repositorio não vejo problemas.
Vc não mostrou como faz queries complexas (filtros , por exemplo) Dependendo da complexidade só ai tlv valha a pena incluir um query object, mas se já usa o JPA 2 provavelmente é um trabalho desnecessário.
Como tudo está dividido se vc precisar disso no futuro pode facilmente adicionar. Por agora, acho que tá show.
Abraços
Olá Sergio obrigado por responder,sim houve um engano meu quiz realmente dizer que chamava o repository em operações de leitura.Tenho algumas consultas bem complexas todas em JPQL estava pensando em migrar para a Criteria do JPA2, ainda não o fiz porque não domino esta API ainda.
Uma outra dúvida que tenho quanto a arquitetura , é sobre o tal do modelo anêmico, vc inclusive já postou sobre isso e compartilho da sua opinião que o pessoal tá vendo fantoches em tudo, mas mesmo assim gostaria de uma opinião.O referido sistema que apresentei o trecho acima é um sistema de auditoria de contratos,onde a entidade Contrato possui um Status e esse status é que gerencia o fluxo do processo
@Entity
public class Contrato{
@ManyToOne
@JoinColumn(name=”st_id”)
private Status status;
}
atualmente na minha arquitetura o código que muda o status do contrato está em minha classe ConTratoServiceImpl
public void enviarContratoRevisao(Contrato c){
Status status = statusRepository.findStatus(STATUSLIST.EM_REVISAO);
c.setStatus(status)
contratoRepository.update(c);
}
é correto eu ter este tipo de operação em minhas classes de serviços ou este método deveria estar dentro da entidade Contrato? é correto chamar meu repositório dentro de minhas entidades?
@Entity
public class Contrato{
private StatusRepository statusRepository;
private ContratoRepository contratoRepository;
@ManyToOne
@JoinColumn(name=”st_id”)
private Status status;
public void enviarParaRevisao(){
Status status = statusRepository.findStatus(STATUSLIST.EM_REVISAO);
this.status(status)
contratoRepository.update(this);
}
}
Abraço.
Eu acho isso meio estranho. Para mim o status não passa de num enum e pronto. Para quê tanta coisa em recuperar um status do banco só para colocar num campo ?
Um enum resolve suficientemente bem essa situação. O status é uma propriedade do objeto nada mais que isso.
public Contrato enviaParaRevisao(){
Contrato novo = new Contrato(this); // copia todos os campos
novo.status = StatusContato.EM_REVISAO;
return novo;
}
depois vc manda para o serviço normalmente
Contrato contrato = …
servico.save(contrato.enviaParaRevisao())
Não vejo vantagem em colocar o repositorio no entidade. isso dá uma dor de cabeça…. antigamente no EJB 2 era para fazer assim e ninguem fazia, agora que o EJB evolui com o JPA vamos andar para trás ? Acho que não.
Se vc quiser pode até criar um outro objeto ContratoState (que controla o estado, não status) conforme alguma regra de negocio e tem acesso a serviços e repositorios, mas o jeito que está fazendo me parece muito complexo sem necessidade.
Boa tarde, agradeço as respostas,realmente faz mais sentido que Status seja apenas um Enum, mesmo que seja uma Enum mapeada com JPA.
Quanto aos repositórios nas entidades, foi só um exemplo,apenas queria saber sua opinião,não uso,acho feio,e dá responsabilidades que não são da entidade não gosto de coisas como activeRecord.
Já me desculpando se eu estiver chato, tenho mais uma dúvida que é sobre a criação de objetos, acredito que o mais correto seria utilizar factories e estas estariam na camada de dominio,estou correto? e de onde eu invocaria minha factory? do repositório,da service ou no próprio Controller? outra se no meu construtor eu precisar de outra entidade,que pra criar um objeto eu precise consultar outros antes.Vamos supor que todo contrato criado já deve estar vinculado a um fiscal(exemplo ruim já teria o fiscal na memória apenas passaria como parâmetro mas é apenas para entendimento)
public class Contrato(){
private Fiscal fiscal;
public Contrato(Fiscal fiscal){
this.fiscal = fiscal;
}
}
é correto eu injetar o repositório dentro da factory para fazer a consulta? ou se eu fizesse:
public class ContratoRepository extends …{
…
@Inject
ContratoFactory factory;
public Contrato novoContrato(Integer fiscId){
Fiscal fiscal = fiscalRepository.find(fiscId);
return factory.createNewContrato(fiscal);
}
}
estaria correto?ou ainda se eu quiser eliminar a factory,por questões de simplicidade, posso delegar ao repositório a criação de objetos?
Não está de nenhuma forma ser chato. Quisera eu que todo o mundo tivesse duvidas como as suas.
Sendo um repositorio comparável a uma lista na memoria , seria preciso criar o objeto antes de enviá-lo à lista. Portanto, não é o repositório que sabe criar os objetos no sentido que não existe RepositorioX.getNovoX(). Isso nos deixa com os métodos tradicionais baseados em construtor, métodos estáticos de construção e factories. Mas factories implicam em que existe uma forma mais complexa que as anteriores e isso não é comum. Quando A depende de B como no seu exemplo vc não cria um construtor A(B) mas sim um campo B em A e valida em tempo de “save” se a relação é correta, obrigatória, etc… mas conceitualmente não ha esse construtor. Contudo pode acontece que seus objetos realmente não tenha construtores publicos. Um clássico são os objetos de valor como Money que normalmente têm algo como Money.valueof(). Bom, no fim, se pensarmos que existe uma objeto que sabe criar o outro seja porque ele invoca o construtor, o método estático ou qq outro mecanismo isso seria uma fábrica. Nesse caso é o repositório que depende da fábrica e não o inverso. O repositório usa a fábrica quando precisar criar os objetos (por exemplo quando os lê do banco) mas a fabrica pode ser usada em outros lugares. Por exemplo no controler quando se transforma algum request nos dados do objeto. A factory existe para substituir o new, então será usada onde normalmente seria usado new.
Normalmente o repositório não trata da criação dos objetos porque ele delega isso a um DomainStore ( O EntityManager é um DomainStore). O domain store se baseia fortemente em metadados e em convenções. Normalmente ele assume que os objetos têm um construtor sem parametros, mas algumas implementações deixa definir como os objetos são criados ( o UserType do Hibernate serve para isso). O único objetivo do repositório na leitura é definir a query, não executá-la. É quem executa que terá acesso à factory. A menos é claro que não utilize uma camada de domain store, mas hoje me dia, duvido. Em ultimo caso será o repositório a saber dar o “new” seja ele explicito ou via factory. Mas normalmente isso existe embutido na camada de baixo. Aliás porque se A depende de B quando eu fizer uma query de A que tem B, o mecanismo precisa saber criar A e B e não apenas A. Portanto o repositório de A teria que saber criar B tb e todas as entidades acopladas a A e B e a essas outras. É por isso que o padrão DomainStore que se baseia em metadados é mais útil aqui. existe um único lugar central que sabe tratar , criar, persistir e reler os ojectos do domínio. Espero ter respondido suas perguntas a contento.
Olá Sergio, esclareceu sim, obrigado!
Olá Sergio, tudo bem?
Tenho lido seus artigos sobre MVC e Arquitetura Java e percebi que você entra em detalhes que são pouco abordados nos artigos que se vê por ai. Mas eu senti falta das referências nos seus artigos, eu queria me aprofundar em entender melhor essa sua visão de arquitetura queria que me indicasse os livros que você leu para obter esse conhecimento.
Obrigado!
Obrigado por ter notado que me preocupo com detalhes que não estão nos livros. Este é o objetivo do blog. A razão é porque os livros costumam ser muito descritivos e por isso limitados na discussão dos porquês e por que nãos.
O que eu comento no blog não tem uma bibliografia associada , afinal esse é o ponto da questão, mas existem sim alguns livros que li. Se eles me ajudaram a chegar nas conclusões ou não cabe a você avaliar, mas eu diria que a lição maior que tirei dos livros é que as pessoas no mercado ignoram muita da teoria que existe e partem para uma prática meia boca sem um estudo prévio e muitas vezes esta prática é contrária à teoria, o que é pior.
Alguns livros seriam
– Padrões de Projeto em Java – Steven John Metsker (Bookman)
– Core J2EE Patterns 2 Edição (Prentice Hall)
– Modelagem Ágil – Scott E. Ambler ( Bookman)
– Software Arquitecture in Practice (Addison Wesley)
– Software Requirements 2 edição – Karl E. Wiegers (Microsoft Press)
– Software Requirement Patterns – Stephen Withall (Microsoft Press)