Neste último ano, derivado da minha experiencia com o MiddleHeaven e meu trabalho com C#, venho tendo cada vez mais a percepção que a linguagem nada mais é uma cola para a API. É a API que produz , que realiza algo e o nosso trabalho é simultaneamente produzir boas APIs e usar boas APIs (é claro que pode usar e fazer APIs ruins, mas isso não é tão divertido … ). Simultaneamente uma linguagem serve para criar a API e uma linguagem que não permita estabelecer regras sobre o uso e construção da API não é uma boa linguagem. Isto despertou dois interesses: a) como seria uma linguagem que é uma boa cola e ao mesmo tempo permite criar melhores APIs e b) quais e como seriam essas melhores APIs.
Ao tentar idealizar uma linguagem orientada a objetos é imediatamente óbvio que linguagens OO precisam de API fundamentais que traduzem conceitos que o compilador e em ultima instancia a VM vão traduzir para operações no processador e na memória. Estas API serão internalizadas (intrinsicfied = to turrn intrinsic ) pelo ambiente e executarão com mesmas regras da API , mas não necessariamente com o código provido pela API. São otimizadas. As linguagens modernas têm tendência a remover os primitivos (valores que só existem no stack e aceleram os cálculos como int e array) e transformar tudo em objeto, mas a compilar tirando partido dos primitivos. Desta forma a linguagem é puramente OO, mas a máquina não é, e isto permite várias otimizações.
É interessante entender como a JVM cria uma camada entre o “verdadeiro metal” – um mundo o C++ é senhor – e o mundo dos objetos. Para isso a JVM é baseada em uma especificação que lhe permite criar um “metal virtual” e dai o “virtual” em Java Virtual Machine. As novas linguagens encaram esta máquina como o “único metal que interessa” e tentam otimizar o uso das suas instruções da mesma foram que o C/C++ tenta otimizar as instruções do processador. Ao mesmo tempo que vemos iniciativas em linguagens como Scala, Ceylon, Kotlin, etc… para uma melhor linguagem , o pessoal da Oracle está tentando que o “virtual” da JVM seja cada vez mais ténue. Conceitos como melhores arrays que permitem ser mapeadas na memoria de forma compativel com C, por exemplo, permite que as bibliotecas Fortran sejam acessiveis em Java “puro” sem uso de JNI/JNA. Esta e outras melhorias previstas para futuras versões da JVM a tornam “A máquina” e por isso é tão interessante desenvolver novas linguagens para ela. Ao mesmo tempo, essas linguagens procuram correr em outras máquinas, especialmente a máquina de javascript do seu browser. Existe muito poder em unificar o código que corre no seu browser com aquele que corre no ser servidor.
As APIs mais fundamentais são aquelas que traduzem valores boleanos, quantidades numéricas (int, long , bigdecimal, etc..), strings , arrays e coleções. Podemos simplificar isto dizendo que arrays são um tipo especial de coleção e que strings são coleções de caracteres, o carácter, por usa vez é um elemento do tipo fundamental Character. Falarei das outras APIs de números em outra oportunidade. Para hoje gostaria de focar na API de coleções. Observando a API de coleções do Java , do .NET e de outras plataformas alguns defeitos se tornam evidentes e que por consequência seriam material para criar melhores APIs. Estas melhores apis associadas a melhores açúcar sintático trariam muitas vantagens para o dia-a-dia da modelagem e execução de programas.
Operações
A coleção é nada mais que um aglomerado de objetos que partilham entre si alguma característica. O código apenas conhece o tipo dos objetos na coleção, o resto, a razão de porque os elementos estão juntos, é apenas conhecida do programador e da lógica especifica do seu programa. A coleção atua como um objeto de uso genérico para manipular aglomerados de objetos. As operações que podemos realizar nestes objetos são variadas mas as mais importantes são : colocar um elemento na coleção, retirar um elemento da coleção, substituir um elemento na coleção, iterar todos os elementos da coleção , saber quantos elementos existem na coleção (cardinalidade/tamanho da coleção) e saber se um objeto está na coleção.
Algumas destas operações não alteram a coleção, como contar o número de elementos , saber se um elemento está contido ou iterar os elementos, enquanto outras sim. Um dos defeitos das coleções em java é que todas as interfaces são simultaneamente de leitura e escrita, embora a maior parte das vezes estamos apenas interessados só na leitura. mais que isso, normalmente estamos apenas interessados na iteração dos elementos. Quando retornamos um List de um método que leu alguma coisa do banco de dados não esperamos que o código cliente altere essa lista, contudo não podemos evitar que algum método modificador seja invocado. O melhor que podemos fazer é usar algum decorador que lance exceção sempre que a operação que não queremos permitir for chamada. Ora , isto funciona, mas obriga o criador do método a ter que declarar e controlar como o retorno do seu método se comportará depois. Isto é uma fuga no contrato (contract leak). Seria melhor retornar uma interface que simplesmente não têm os métodos de modificação; uma interface só de leitura. Isto deixa claro ao utilizador do método a intensão do criador do método.
A API de coleções do .NET ( estou falando da que é genérificada, não da mais antiga) tem uma abordagem um pouco melhor criando variantes ReandOnly das coleções como IReadOnlyList e IReadOnlyDictionary (Dictionary equivale a Map em java). Contudo o design do .NET é claramente incompleto e ambíguo, para dizer o mínimo, pois existe uma interface ISet , mas não uma IReadOnlySet.; e as versões mutáveis não herdam das imutáveis o que torna as coisas estranhas. Um IDictionary não é um IReadOnlyDictionary, embora tenha os meso métodos e se comporte da mesma forma em relação à leitura. Escrever um método de extensão que permita usar ambos é um desafio pois não ha herança entre eles. A API reconhece que existem dois tipos de imutabilidade, mas não forma hierarquias corretas entres essas formas o que leva a problemas e usos estranhos.
A API .NEt tem um método IsReadOnly, mas o seu significado é estranho. Se tivermos um array , ele implementa a interface IList e retorna false em IsReadOnly. Isto é correto pois podemos modificar os elementos usando array[index] = elemento, mas é errado porque não podemos usar os métodos add e remove de IList. O tamanho de um array em .NET é inalterável , tal como em java, mas isso não é traduzido nos métodos que estão disponíveis. Confuso.
Formas de Imutabilidade
As novas plataformas como Scala e Ceylon dão bastante importância à imutabilidade. Inclusive no nível de distinguir entre “variável” e “constante”. A razão para isto é que existem várias otimizações possíveis, inclusive ( e principalmente) na capacidade de realizar as operações em paralelo. Se sabemos que determinada coleção não será modificada por outra parte do código várias otimizações podem ser feitas pelo próprio objeto a fim de diminuir a memória ocupada e o tempo de execução das suas operações. Estas linguagens tendem a cria interfaces de coleção e depois criar versões “imutáveis” dessas coleções (como faz o C#, exemplificado antes). Contudo estas versões imutáveis sempre deixam um hiato conceptual.
Uma coleção de objetos é mutável em dois sentidos. Se objetos são adicionados ou removidos da coleção dá-se uma mudança no tamanho da coleção. Se um objeto é substituído por outro, dá-se uma mudança no conjunto de elementos sem haver mudança no tamanho. Dizer que a coleção é imutável é ambíguo a menos que se especifique em relação a qual propriedade nos referimos. Neste texto, quando digo “imutável” me refiro a não ser nem editável nem poder mudar de tamanho.
Digamos que uma coleção que pode mudar de tamanho é Resizable (Aditável) e uma cujos elementos podem ser alterados “in loco”, é Editable (Editável). A coleção, ela mesma é imutável até que apresente uma destas características.
Com esta nomenclatura vemos que todas as interfaces de coleção presentes no java e no .net são Resizable e Editable por definição e que apenas com truques de implementação podemos fazê-las não ser. O .net vai um pouco mais longe e chega a definir interfaces que fornecem a versão que não é nem Editable nem Resizable, a versão ReadOnly, contudo ela não é usada de uma forma homogenia.
Estas características são importantes ao analisarmos o conceito de array. Um array, claro, não é imutável podemos escrever e ler seus elementos com array[index], mas o tamanho é fixo. Portanto, neste conceito um Array é uma coleção que é apenas Editable mas não é Resizable. Uma Lista que em tudo se parece a um array, tem a propriedade suplementar de ser Resizable e é isso que gostamos nela ( usar o método add()). Não precisamos saber à priori quantos elementos iremos colocar nela.
Variância
A variância é uma propriedade interessante de classes genéricas., da qual já falei antes. A variância está relacionada à imutabilidade da classe. Com todas as classes de coleções em java, são mutáveis isso obriga que elas sejam invariantes e a não ser possível atribuir uma lista de strings a uma lista de objetos. Tudo bem que na prática isto é quase irrelevante, mas prova que a linguagem é limitada.
Mas, o que acontece se tivermos perante um interface só de leitura ? Se a interface for só de leitura ela é co-variante por natureza pois não como “enganar co compilador”. Esta conclusão é chave para entender a novas linguagens e APIs. Devemos dar preferência a interfaces só de leitura no nosso código e apenas onde o programador precisar criar um objeto que implementa aquela interface é que ele terá, provavelmente , que usar uma implementação mutável. Isto inibe o resto do programa de manipular incorretamente a interface e obrigando o programa a criar cópias sempre que os seus algoritmos forem modificar a coleção.
Iteração e Streams
Como falei, uma das operações importantes é iterar os elementos da coleção. Isto é normalmente feito com uso da diretiva for-each. O compilador entende que existe uma interface especial (Iterable em java, IEnumerable em .NET) que fornece um conjunto de métodos de forma que os elementos podem ser iterados. Na realidade nada mais é que um açucar sintático para o uso de while, que é a única diretiva realmente “nativa” da jvm. Este é um ótimo exemplo de como a linguagem que ser uma cola para a API. O programador poderia usar a API pura, sem açúcar sintático. Seria chato, mas possível. Mas ao abstrair o conceito de um objeto que contém outros e permite iterará-los em uma interface, o compilador pode ajudar e a linguagem se torna mais elegante, simples e poderosa. Inclusive , em java, um array não implementa Iterable, mas o compilador entende iterar os elementos de um array com a mesma sintaxe que os elementos de um Iterable. Em .NET como um array é um IList que por sua vez é um IEnumerable, está embutido no tipo Array que o for-each irá funcionar com ele. Ou seja, em .NET o array é um primitivo que se comporta como se não fosse pois está implementando as interfaces padrão da API de coleções. Em java um array é um primitivo e não tem como ele implementar interfaces especiais.
Uma evolução da iteração é o encapsulamento da diretiva de iteração dentro de um objeto Stream que permite realizar várias operações enquanto a iteração acontece. Falei disto no post passado. Uma nova API de coleções tem que levar este conceito a sério. Em Scala, por exemplo, não existe o for-each que estamos acostumados. Apenas existe a notação nomádica associada ao fato de Stream ser um monad, ou seja, todos os for são execuções de streams. Esta notação é muito semelhante ao Linq e pode ser completamente modificada para só usar objetos e não usar diretivas primitivas como while ( mas tem grandes diferenças na implementação como veremos depois) Paralelamente, outro monad importante quando falamos de coleções é o Maybe/Optional que também já abordei ha alguns anos atrás.
Uma nova API de Coleções
Dito tudo isto, vemos que temos que priorizar a criação de interfaces apenas de leitura que devem ser iteráveis e podem ser fontes de Streams de elementos. Estas operações são mais que suficientes para qualquer programa. A única razão para precisarmos de interfaces e implementações mutáveis é a necessidade de colocar os elementos na coleção, copiar de outras coleções, etc… ou seja, operações que adicionam ou removem os elementos da coleção.
Irei argumentar que criar uma API de Coleções para seu uso pessoal/empresarial que respeita as regras corretas em relação aos conceitos de imutabilidade deixa mais clara a intensão dos programadores em permitir ou proibir alterações à coleção. O uso destas interfaces tornarão seu código muito mais fácil de manter. Usando contratos mais específicos para sua coleções elimina a necessidade de ter que documentar se as coleções retornadas e recebidas poderão/serão ou não modificadas pelos métodos ou por quem os invoca. Isto leva a menos erros de programação – sim, por que afinal, quem é que lê a documentação ? e dos que leram quem se lembra de tudo ?
Veja que criar uma API destas não significa, em primeira aproximação, criar um monte de implementações novas de list, set, etc… não é este o problema que estamos tentando resolver. O nosso problema é na modelagem dos conceitos e das interfaces que os representam. As implementações podemos muito bem acabar delegando para as implementações que já existem. Por isto, para criar um nova API de coleções o nosso guia será o principio de Segregação de Interfaces ( um dos princípios SOLID) acoplado com o principio de responsabilidade única (SRP , também do SOLID), que no caso, diz respeito a se a coleção é imutável, editável e/ou aditável. Para simplificar vou me ater apenas a um exemplo em Java, mas o raciocínio pode ser portado para .NET facilmente. (Como nota é relevante mencionar que os nomes dos métodos das interfaces têm que ser coerentes com os nomes nas respetivas plataformas. especialmente se esperamos que em algum ponto nossas classes implementem as interfaces que já existem nas apis padrão da plataforma)
A raiz de tudo tem que ser a interface Iterable. É ela que se acopla à linguagem e permite realmente executar as iterações nas coleções. Depois precisamos de um conceito que traduza o conceito de coleção imutável. Esta coleção não permite muito. Apenas iterar, contar os elementos e saber se um elemento está presente. No caso do java ela permite também obter uma Stream para os elementos. Para contar , introduzimos a interface Countable que contém o método size() e isEmpty(). A razão de isEmpty é que em muitos casos é possível saber se existem elementos sem ter que os contar. Isto aumenta a performance e a legibilidade da API.
Vamos batizar a nossa interface principal da API de coleções de Assortement<T> (sortido, arranjo) que implementa Iterable e Countable e contém o método contains(Object obj). Repare que contains não é de T é de Object. Isto é para não violar a variância da interface. em outras linguagens talvez existissem outros truques relativos à declaração da variância. O idela é declarar que contains recebe T ou filhos de T, mas que isto não torna a interface contra-variante (porque o elemento não estão sendo colocado dentro da classe). Não conheço uma linguagens que tenha este nível de especificação na sua sintaxe.
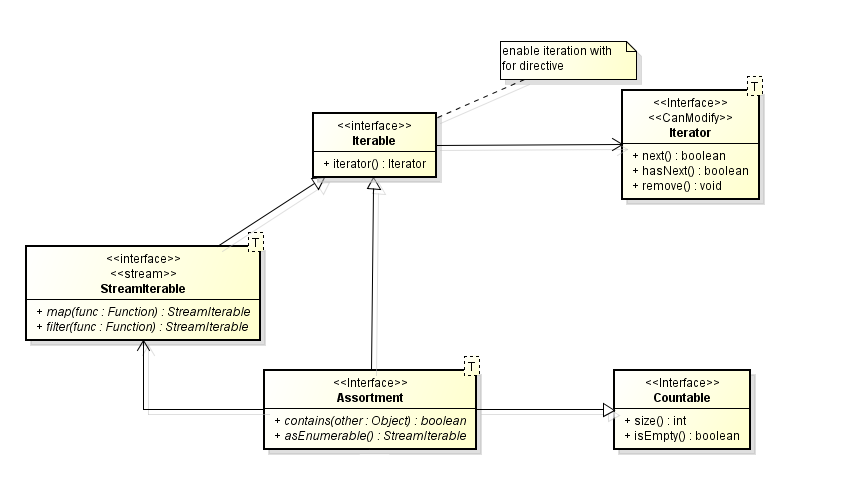
Agora podemos pensar em três tipos principais de Assortments, aqueles que são indexados pela posição, os que são indexados por chaves e os que não são indexados. Os primeiros chamaremos de Sequence<T> e os segundos de Association<K,V>. Para os terceiros ha várias opções já que Set, Queue, Deque vão estar nessa parte da herança. Mas, por brevidade, vamos nos ater aqui aos mais fundamentais para entendermos a construção da API. Repare que Sequence<T> é o tipo imutável de List<T> e array T[] e Association<K,V> é o tipo imutável de Map<K,V>.
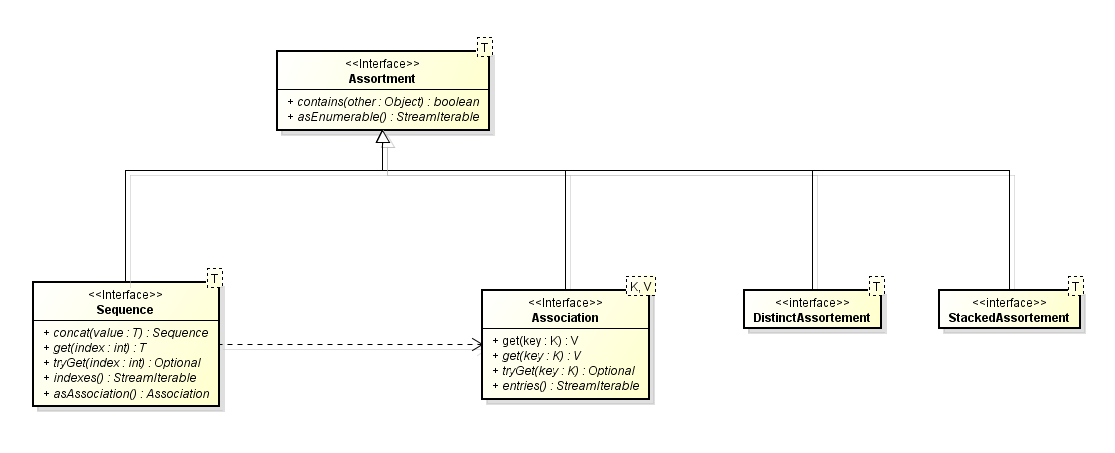
Em Sequence as operações são simples. Apenas um get(index) é adicionado para ler o elemento na posição dada. Contudo, muitas operações derivam do conceito de ter uma coleção indexada de elementos (pense nas operações que você usa com array e String). Operações como obter subsequencias, inverter a ordem, ordenar, filtrar, transformar, etc.. podem ser feitas em sequencias e obter outras sequencias. Repare que este tipo de operações permite obter novas sequencias sem modificar as sequencias originais. O mesmo tipo de operações pode ser feito para Associations.
Uma operação interessante é iterar os elementos ao mesmo tempo que os índices. Para associações isto é bastante comum quanto iteramos os pares chave-valor. Para sequencias isto não parece tão necessário, mas de fato fazemos isto de uma forma não explicita quando iteramos uma lista por índice. As nossas coleções entregam um StreamIterable (um stream) para prover esta capacidade.
Poderíamos agora argumentar que todas estas operações poderiam ser feitas via stream e isto traz escolhas interessantes. Usemos o seguinte exemplo para ilustrar: A ideia é ter uma sequencia e criar uma subsequencia de elementos. Usando o conceito de stream poderiamos fazer (não estou usando o Stream padrão do java, seria uma outra – StreamIterable – que vai junto com a nova api de collections)
Sequence<String> seq = Sequence.of ("a", "b", "c"); Sequence<String> subseq = seq.asStream().skip(1).toSequence();
Fazendo diretamente, à semelhança de como fazemos com List.SubList ou String.subString :
Sequence<String> seq = Sequence.of ("a", "b", "c"); Sequence<String> subseq = seq.subSequence(1);
Repare agora nas diferenças. No segundo caso não temos realmente que criar um nova sequence. Apenas precisamos devolver uma “view” deslocada de 1 posição com size = original -1. Isto permite não apenas poupar memória, mas também processamento. Não ha nenhum laço envolvido aqui. Já na primeira opção temos que criar o objeto de Stream, e depois executar um laço interno para criar uma outra sequencia. Se a sequencia tem N elementos e pretendemos desprezar os primeiros K a primeira operação é O(N-K), enquanto a implementação com “view” é O(1).
Podemos usar “views” porque temos a certeza que a sequencia não será alterada nunca. Este contrato é mais útil quando estamos fazendo operações de leitura.
O caso se adensa quando pensamos em métodos como filter e map. Por exemplo,
Sequence<String> seq = Sequence.of ("a", "bb", "ccc"); Sequence<Integer> subseq = seq.asStream().skip(1).map( c -> c.length()).filter( i -> i % 2 == 0) .toSequence();
e , diretamente seria
Sequence<String> seq = Sequence.of ("a", "bb", "ccc"); Sequence<Integer> subseq = seq.subSequence().map( c -> c.length()).filter( i -> i % 2 == 0) ;
Agora temos um problema maior, a cada transformação temos que executar toda a transformação e criar uma nova Sequence. A ideia de “view” não funciona pois os objetos não são mais os mesmos, temos que realmente criar novos objetos (definidos com a operação map) e colocá-los em uma nova sequencia. O mesmo para filter. Nem o tamanho nem os elementos são os mesmos. Temos que relamente que processar os elementos e produzir a sequencia. Isto significa ler os N elementos para cada operação. Se realizarmos P operações a performance será então O(P * N).Esta é a técnica usada pelo Scala. Quando usamos a stream , o próprio conceito de stream garante a máxima performance possivel que no caso é iterar apenas uma vez e portanto a performance é proporcional a O(N) não importa quantas operações realizemos. Ha portanto uma redução por um fator de ordem O(P).
O C# utiliza esta técnica de stream. Tudo é feito com stream e converte no fim , se quiser. Em c# esta técnica é uma melhor escolha porque o conceito de Stream está embutido no conceito de Iterator, ou seja, todos os Iterables (IEnumerable em .NET) podem ser transformados, portanto não precisamos de “asStream”. Depois existe o conceito de Extention Methods que permite adicionar métodos a classes onde eles não existiam antes. Logo, criar um ToSequence a partir de um IEnumerable é trivial. Em java com as nova API de Stream este conceito também é seguido.
Poderíamos fazer nossa interface Assortement ter todas as operações de Stream como map e filter, simulando o que acontece em C#, mas sempre o retorno desses métodos seria a mesma classe que iniciou o processo. Isto torna as assinaturas das classes e dos métodos um pouco exotérica, mas seria possível. Assim não precisaríamos com conceito de Stream. Por outro lado, um Assortement não é um Stream.
Não ha um claro vencedor aqui, mas está claro que as propriedades da linguagem estão interferindo fortemente nas nossas considerações de design. O ideal é realmente ter uma nova linguagem.
Em java, para desempatar a consideração é que nem todas as classes precisam de métodos especiais mas o conceito de Stream é vital. Por exemplo, não ha muita operações com Association. Portanto teríamos uma solução hibrida. Sempre é possível usar a API de stream e converter no final, ou usar os métodos específicos. Para os casos que queremos uma api mais fluente, essa classe teria métodos especificos, como Sequence.subsequence.
Na prática isto é aceitável porque podemos usar o mesmo conceito de view de antes ( sim, eu falei que não poderia, para criar efeito, 🙂 ). A ideia é que sempre que invocamos map, filter, etc. em Sequence, criamos uma view que contem a Stream que resultaria da mesma operação. Quando os métodos especificos de Sequence são chamados pela primeira vez , lemos o stream e criamos um sequence com os elementos resultantes. É uma especie de lazy inicialization. A vantagem é que não precisamos iterar a cada passo, apenas quando o programa tentar ler a sequencia.
Falando idealmente o modelo do C# é melhor em que a interface que é entendida pelo for-each seja a que tem uma semântica de Stream. Assim, todas as classes de coleção são imediatamente fontes de stream. O pessoa do java não implementou asStream diretamente em Iterable o que estraga um pouco a experiência de uso da api de steams.
Editable e Resizable
Agora que temos nossa Sequence e Association imutáveis temos que entender como chegar nas versões mutáveis.O primeiro passo é manter o mesmo tamanho do Assortement e apenas editar os elementos. Para isto criamos EditableSequence e EdiableAssociation. Estas interfaces adicionam o método set(index, obj) e set(K key, V value)respectivamente e permitem substituir elementos. EditableSequence é na realidade um Array e de fato este poderia ser um bom nome para a implementação padrão de EditableSequence : ArraySequence. Em Kotlin, por exemplo, one não existem arrays primitivos, a classe Array<T> tomo seu lugar. Esta classe tem o mesmo comportamento de EditableSequence. Repare que esta interface, por permite edição, não é mais covariante. Ela precisa ser realmente invariante (não que isto faça diferença em java, mas faria em .NET ou em outra linguagem que permite manipular variância)
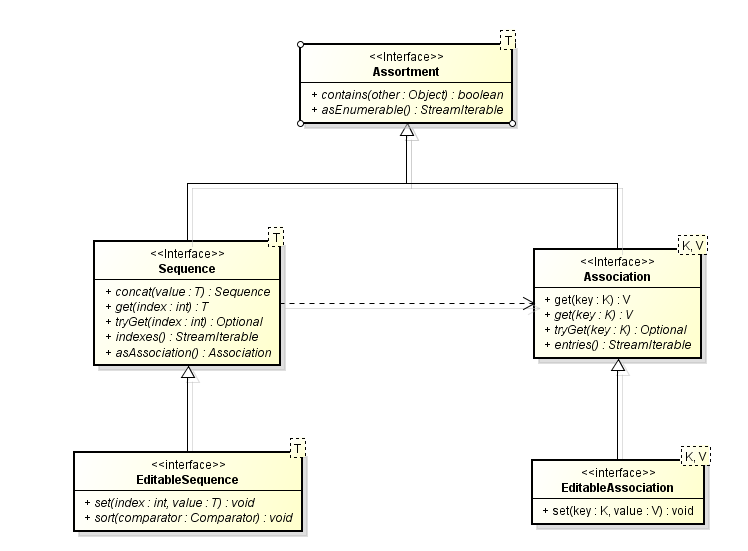
Porque sabemos que a sequencia é editável, sabemos que podemos permutar os elementos, o que nos permite definir a operação de sort. Esta operação altera a própria sequencia. Para ordenar uma sequencia imutável teríamos que criar um outra sequencia o que pode ser feito com uma operação de stream. Isto também justifica a escolha de não tornar Assortment um StreamIterable pois existirão métodos com nomes e sintaxe muito semelhantes mas que não têm a mesma semântica.
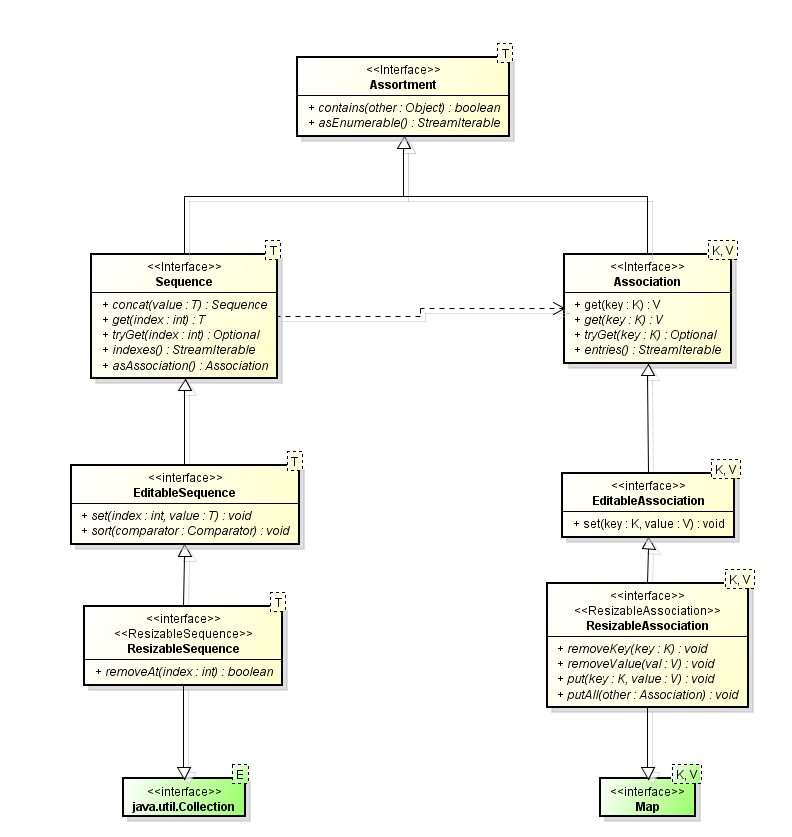
Finalmente adicionamos a capacidade de modificar o tamanho com os métodos add/remove e suas variantes. Agora temos um ResizableSequence e um ResizableAssociation. Estas interfaces são na realidade um-para-um com as interfaces tradicionais da API java como List e Map respectivamente e as implementam. As implementações padrão destas sequencias seriam ListSequence e HashAssociation. Claro que outras variantes podem existir como LinkedListSequence, por exemplo. Todas em correspondência com as várias implementações que já existem atualmente em java e que premiam certos detalhes de implementação para obter melhor performance.
Outras Coleções
Além de Sequence/List , Association/Map e todos os outros pares imutáveis para as classes atuais, ainda haveria que considerar outras coleções que não existem em Java. Por exemplo, MultiSet (também chamado bag) – que conta quantas vezes um elemento está no conjunto e só guarda uma cópia – , MultiMap – que mapeia uma chave com uma Lista ou um Set de elementos e ReversableMap que permite mapear chaves para valores e valores de volta para as chaves.
Estas interfaces imutáveis juntamente com suas variantes Editable e Resizable são boas adições e simplificam vários algoritmos inclusive ajudando a aumentar a performance final do programa.
Implementações
A vantagem de ter uma hierarquia de interfaces completa é que não importa realmente qual é a implementação que usamos. Podemos delegar para as implementações que existem na API Java, podemos criar nossas próprias implementações ( o que é interessante e desafiador, mas pode incluir bugs difíceis de detectar e piorar a performance) ou podemos delegar para API de terceiros que são mais especificas ou rápidas que as do Java. A API Apache Commons Collections me vem à memória. Esta API existe antes da API padrão do Java e ainda existe hoje. Ela já inclui o conceito de MultiSet, MultiMap, Mapa reversível (que usa valores para obter as chaves) etc… É a implementação usada pelos projetos Apache o que vai ao meu ponto que sua empresa deveria ter uma API de Collections própria. Um outro exemplo é a API Guava do Google que segue o mesmo conceito. E para não ficarmos nos exemplos de sempre, temos ainda o exemplo da Goldman Sachs Collections como comentou o Douglas Arantes no post sobre Streams. Obrigado Douglas. Esta API está bem documentada com várias comparações com Scala sobre a performance. Vale a pena conferir. Este estudo prova que realmente o design da API impacta diretamente na performance.
A API Guava inclusive inclui o conceito de Stream através da interface FluentIterator, o que realmente deixa bem claro que o um Stream é um tipo especial de Iterator e fica mais próximo do conceito existente em .NET em que realmente é a mesma coisa – IEnumerable faz os dois papeis.
Todas estas APIs têm em comum serem desenhadas por empresas para seu próprio uso. Se depois isso vira open source. O que quero dizer com isso é que as empresas devem criar API para facilitar a sua vida, mesmo que isso pareça “reinventar a roda” traz vantagens. Além de que como você controla tudo na interface você pode incluir coisas novas no futuro.
Uma API prórpia permite também um design mais limpo. O programador pode expressar conceitos que a API padrão padrão não permite. Por exemplo, se você tem um método que lê do banco e retorna um Sequence você tem a certeza absoluta que não será possível modificá-l, mas não se retornar List. O custo de mais controle sobre o funcionamento da aplicação é a criação de APIs que controlam melhor. Tão simples quanto isto. Não precisa de exceções, decoradores, e outros truques que se usam no java. O código fica mais claro, mais imutável e portanto com menos probabilidade de alguém fazer asneira.
As empresas e os programadores têm tendência a apenas usar a API padrão da plataforma. Mas esta API pode ter problemas de design, performance, contrato, etc… que atrapalham mais que ajudam. A API padrão é interessante quando a) você não sabe ou não precisa fazer a sua e b) para interoperabilidade com outras APIs da plataforma ou de terceiros.
Raramente você precisará criar um API que substitui a da plataforma, mas no caso da API de coleções existem bons argumentos para repensar essa regra. Talvez seja a exceção que confirma a regra. A desculpa padrão para não fazer isto é que “estamos reinventando a roda” e que a equipe não tem capacidade para implementar todos os detalhes. Pode até ser verdade mas lembre-se que estamos apenas desenhando interfaces e relações entre elas. As implementações reais podem ser as que já existem implementadas e podemos usar APIs de terceiros. Existem até técnicas para plugar a implementação que mais estiver correta sem mudar o código que usa API. É tudo uma questão de adicionar mais design.
Parabéns pelo post!