Iremos aborda as três principais arquiteturas atuais : Arquitetura Clean, Arquitetura em Cebola (Onion) e Arquitetura Hexagonal. Veremos o que é comum entre elas e porque elas definem uma família de arquiteturas chamadas Planas.
Arquitetura Clean
“Clean Architecture” (Arquitetura Clean) é o nome de um livro de uma ideia proposta por Robert C. Martin, ( aka Uncle Bob). O tema também é abordado no seu blog e em várias palestras. A melhor seria esta que faz parte de um conjunto de palestras que resumem a obra de Robert C. Martin.
O nome “Clean Architecture” não se traduz por Arquitetura Limpa, mas melhor por Arquitetura Despojada ou Arquitetura Enxuta- uma arquitetura sem excessos. Usarei o nome Clean para me referir a ela.
Como vimos antes, “uma arquitetura” é o nome que damos a um conjunto de decisões especificas que formam um padrão de decisões irreversíveis (hard). A arquitetura Clean é construida no livro com base nos Princípios SOLID. Cada principio age de uma força especifica para moldar o raciocínio e as decisões que formam a arquitetura final. Portanto, esta arquitetura pretende ser obtida de primeiros princípios de design, e com isso garantir implicitamente a boa aderência aos Princípios SOLID, embora eles não sejam mencionados especificamente na arquitetura. Não é, portanto, uma arquitetura para resolver um certo problema, mas uma arquitetura modelo para ser usada como base para pensar arquiteturas reais.
Normalmente a arquitetura clean é representada, na sua forma mais simples, assim:
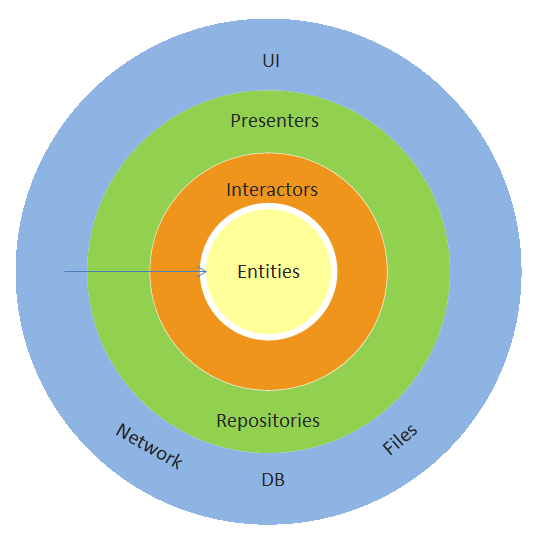
Cada cor representa um conjunto de classes com propósito especifico – uma camada. A camada mais externa interage com os limites de I/O – entrada e saída do sistema. O input em uma camada é transformado para um input na camada seguinte e assim sucessivamente até chegar no centro. Nesse ponto um output é processado e encaminhado de volta até sair do sistema pela camada mais externa. O numero de círculos não é realmente importante e podem haver vários, mais ou menos do que os apresentados aqui. O importante é que quanto mais perto do centro mais estável é seu código.
Este conceito é muito semelhante a outras arquiteturas propostas como a Arquitetura em Cebola de Jeffrey Palermo ou a Arquitetura Hexagonal de Alistair Cockburn.
Regra de Dependência
A única e mais importante regra nesta arquitetura é que:
dependências de código fonte só podem apontar para dentro.
Isto significa que as classes nas camadas externas podem depender das classes na camada interna imediatamente seguinte, mas as classes nas camadas internas não podem depender das classes da camada externa. Esta regra se aplica a todas as classes inclusive a aquelas classes que só contém dados. Cada camada tem a sua coleção de classes de dados que pode ser acessada pela camada de fora, mas não pode ser passada à camada de dentro. Isto implica em que os dados terão que ser constantemente convertidos entre camadas.
Este conceito de “dentro” e “fora” – presente também nas arquiteturas Hexagonal e de Cebola – contrastam com os conceitos de “cima” e “baixo” presentes na arquitetura de camadas clássica em que as camadas formam uma pilha.

A grande diferença entre as arquiteturas Clássica e Clean é que a última coloca as camadas abaixo das entidades como dependentes das camadas anteriores. Numa pilha isto não faz sentido, dai o conceito de círculos.

No desenho original camadas como UI e DB (Banco de Dados) ocupam o mesmo circulo, assim como Presenter e Repository. Isto poderia nos levar a pensar que a UI pode chamar diretamente o banco de dados. A principio não queremos isso, então uma representação melhor seria algo como isto:

Esta também é uma representação muito comum da Arquitetura Clean, mas há uma melhor diferenciação de responsabilidades de adaptação, mais próximo do conceito de Portos e Adaptadores da Arquitetura Hexagonal em que cada “gomo” age com um Porto ou Adaptador especifico e “plugável“. Mesmo assim ainda não é muito claro se os gomos podem depender de outros da mesma cor. Ou se, por exemplo, o gomo de DB poderia chamar o gomo de Presenter. Afinal está numa camada mais interna imediata.
Se prestarmos mais atenção ao detalhe do livro, realmente este diagrama não aparece lá. O que aparece é este outro:

Que colocarmos um pouco de cor para identificar as várias camadas , ficaria assim:

E aqui podemos claramente ver que há dependência entre o Repositorio (chamado de DataMapper) e a camada de Use Cases – até ai tudo bem – e as entidades – que não deveria acontecer considerando o modelo de círculos já que passaríamos pelo circulo laranja para ter acesso direto ao circulo amarelo.
Então realmente tem algo que não fecha nesta representação de círculos. Ela ajuda para termos ideia dos conceitos, mas na prática demonstra uma falha em seguir as regras de dependência.
Por outro lado, o repositório tem que trabalhar com entidades, é o seu propósito principal. Mas como podemos ver o desenho original não menciona Repositórios e sim DataMappers. A diferença é sutil, mas tem que ver com a nomenclatura. O livro do Robert C. Martin não adota em nenhum ponto os conceitos de Domain Driven Design (DDD) e nem o padrão Repository, explicitamente. Ele adota um modelo mais simples. Inclusive, como veremos, um modelo simples de mais. Mas, verdade seja dita, ele está apenas ilustrando um ponto, e não definindo a arquitetura toda com um só desenho. O ponto é exatamente o de ter fronteiras bem definidas e as regras de dependências através dessas fronteiras. Em outros momentos, como nas palestras o Robert C Martin usa este outro modelo :

É quase a mesma coisa, mas não é bem. Repare que aqui o Interactor depende de duas interfaces. Uma que ele implementa e uma que ele usa. O retorno é feito através de uma interfaces e não apenas por retorno de função. Neste modelo os métodos nas interfaces verdes são todos com retorno void. Neste modelo, o estimulo continua vindo do controlador, é transformado para um objeto de requisição (RequestModel) que é passado ao Interactor. O interactor interage com as entidades e com o EntityGateway e produz uma resposta (ResponseModel) que é passado À segunda interface. Ele não é retornado pela primeira interface. O Controller nunca sabe que foi o resultado. O resultado cai no Presenter que o trasnforma para um ViewModel e o envia à view.
O que é importante neste modelo é que :
- Existem fronteiras rígidas bem definidas (mostradas pelas linhas duplas)
- As dependências atravessam essas fronteiras sempre no sentido “para dentro” em direção a onde estão as regras.
Não podemos levar o desenho mais longe que isso. O seu objetivo é mostrar apenas essas duas regras. Se formos implementar isto vamos cair em alguns problemas práticos e lógico. Por exemplo, o Presenter e a View deveriam formar um padrão Model-View-Presenter. Este é um padrão bem conhecido que tem tem uma UML como esta:

Ambos lados só conhecem a interface do outro e comunicam por meio de ViewModels. Repare que isto é muito semelhante ao modelo do interactor. Significa isso que o interactor funciona como um presenter ? Poderiamos respeitar as mesmas regras sem ter o interactor ? Sim. Vejamos:

Temos menos classes mas temos os mesmos conceitos de fronteiras rígidas e a mesma regra de dependência sendo respeitada. Inclusive colocamos a interface de Gateway em outro camada sem incorrer em nenhuma violação.
O modelo original proposto no diagrama do Robert C Martin separa o canal de Requisição do canal de Resposta. Isto pode feito usando interfaces, como ele fez, mas há outras opções como usar Promessas ou Futuros. Para um modelo síncrono a separação em tantas interfaces pode ser em demasia e mesmo para modelo assíncrono existem outras opções. A vantagem principal do design do Martin é que nenhum dos objetos tem que saber se a chamada é síncrona ou assíncrona, mas não explica muito bem como o estimulo chega no controlador se não vem da view. Embora seja um bom modelo para explicar o padrão e as regras da arquitetura não necessariamente é um bom modelo de implementação prática.
Vimos então que existem, na minúcia do detalhe de implementação, algumas arestas que não foram totalmente limadas.
- Não são bem definidas as interfaces que o Interactor usa. Uma parece ser a própria interface do interactor e segunda se parece mais com um canal por onde o interactor responde.
- Por outro lado, este design não é estritamente necessário. Ele pode ser bastante útil num ambiente assíncrono, como uma UI desktop ou um sistema web com Websockets, mas em geral complica para um processamento síncrono. Além disso há outras formas de tornar o processamento assíncrono. Interactors não são, estritamente falando, necessários.
- Não é claro quais “gomos” podem ser usados quais outros. Algum policiamento e cuidado é necessário por quem implementar a real arquitetura. As responsabilidade de ponto de entrada ou saída não são explicitas
- Não há menção ou referencia a DDD – Embora isto seja proposital para não ter que entrar no detalhes do que é uma Entity, já que não é o foco, nos deixa sem saber se essas entidades são o mesmo que as entidades do DDD e/ou se há alguma relação entre elas.
Em suma, é um bom começo mas quando tentamos operacionalizar os detalhes começamos a ter problemas. Acho que o que é realmente importante é a Regra de Dependência e a reversão de dependência que existe entre as camadas classicamente consideradas “baixas”, que nos leva o conceito de circulo. Contudo, ainda temos, mesmo que implicitamente considerar que certas relações não fazem sentido do ponto de vista de fluxo (como a UI chamar o banco de dados)
Arquitetura em Cebola
Esta arquitetura tem os mesmos princípios e visa os mesmos objetivos que a Arquitetura Clean. Mas o seu autor, Jeffrey Palermo, nos dá uma visão um pouco diferente da nomenclatura a usar para cada circulo

Repare que o todos os círculos amarelos são considerados o coração da aplicação – Application Core – e a parte laranja é considerada limítrofe.
Esta arquitetura leva em considerações conceitos como Domain Service e Domain Model advindos de Domain Driven Design. O conceito de Application Service é introduzido como camada exterior que comunica com a UI.
Este modelo nos dá melhores pistas. Ele introduz conceitos de DDD que estavam faltando na Arquitetura Clean e se liberta de conceitos como Presenter e Controller que são demasiados presos a conceitos de UI.
O conceito de Interactor é substituído pelo de Application Service que é mais lato e mais familiar. Na camada de Application Services podemos ter interators, como vimos antes. Mas, normalmente não são necessários a menos que tenhamos necessidade de usar canais assíncronos.
Contudo, a proposta em Cebola ainda tem o mesmo problema de orientação de fluxo. Inerentemente, pelos nomes, sabemos que o estimulo começar na UI e de alguma forma vai até ao banco de dados por meio da camada de Application Service, mas o diagrama nos deixaria igualmente pensar que o estimulo começa no Banco de dados e segue até à UI. Precisamos diferenciar entre o que está a montante e o que está a jusante do fluxo.
Arquitetura Hexagonal
A proposta da Arquitetura Hexagonal é uma pouco mais alto nível que a Clean e de Cebola , embora o conceito base é o mesmo. Ela é representada normalmente assim:

Temos o mesmo coração da aplicação – Application Core – ao centro, que na Arquitetura em Cebola mas há duas regiões bem demarcadas. A região de entrada (em azul) e a de saída (em roxo). A aplicação, ao centro, apresenta portos (port) que atuam como tomadas, com interfaces bem definidas e cada região detém adaptadores (adapter) que conectam o mundo externo à aplicação.
A Arquitetura Hexagonal define um fluxo em que os adaptadores de entrada dizem à aplicação o que fazer. A aplicação, por sua vez diz aos adaptadores de saída o que eles têm que fazer. A informação viaja da região de entrada para a de saída e de volta para a de entrada através da aplicação.
Este é o ingrediente que faltava. Embora todas as arquiteturas considerem a Regra de Dependência, a Arquitetura Hexagonal adiciona o conceito de regiões e fluxo. Temos então duas direções.
Arquitetura Plana
Sendo que temos duas direções possíveis para expandir nosso design podemos dizer que temos uma Arquitetura Plana, em contraponto a uma arquitetura linear utilizadas na pilha de camadas.
Sendo que temos duas direções, temos duas regras:
- dependências só podem apontar para dentro.
- o fluxo da informação é de uma metade para outra, e de volta
Notar que esta segunda regra é na realidade a mesma usa na arquitetura clássica de pilha de camadas. Que no caso era enumerada ligeiramente diferente, mas com o mesmo sentido:
o fluxo de informação é de “cima” para “baixo”, e de volta.
Entendendo as duas regras, podemos resumi-las num diagrama ligeiramente diferente:
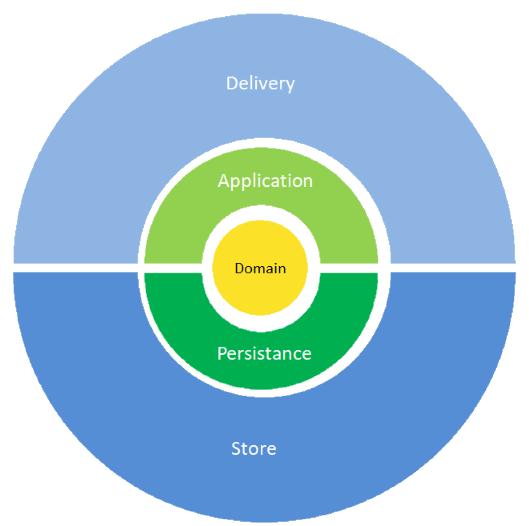
Aqui temos as mesmas ideias de camadas internas e externas separadas em duas regiões (claro e escuro) com o Domínio no centro.
- Entrega (Delivery) – interação com o mundo externo. Este mundo pode ser um ser humano ou outro sistema. Nesta camada cabem responsabilidades de captura de informação e intenção do usuário. Não necessariamente é necessário uma interface gráfica ou uma linha de comandos. Pode bem ser apenas uma API REST ou SOAP ou o fim de um canal de mensageira.
Esta camada é responsável por acolher as demandas do usuário e entregar o valor contido na aplicação - Aplicação (Application) – inclui as regras especificas à aplicação como os casos de uso, mas não só. Serviços de orquestração de fluxo também ficam aqui. Aqui, ficam a maior parte das regras do sistema e é onde devemos procurar para saber “o que o sistema faz”.
Esta camada é responsável por automatizar e conectar as demandas do usuário com quem as pode executar. - Dominio (Domain) – aqui ficam as regras de dominio que são comuns entre esta aplicação e outras. Esta camada é moldada conforme as regras de Domain Driven Design e pode conter não apenas Entities, mas também Domain Services, Specifications e outros objetos do domínio.
Esta camada é responsável pelas regras de domínio. As regras de domínio são aqueles que teriam que ser executadas mesmo se não houvesse software. - Persistência (Persitence) – Esta camada implementa as interfaces dos repositórios do domínio, mas também pode implementar gateways ou datamappers utilizados diretamente pela camada de Aplicação.
Esta camada é responsável por automatizar e orquestrar as demandas da região de saída de forma semelhante à camada de aplicação faz na região de entrada. - Reserva (Store) – aqui ficam as reais implementações de comunicação com disco, banco de dados ou outros. Seria aqui usaria seu ORM preferido ou seus objetos DAO
Esta camada é responsável por demandar outros sistemas para obter informação ou serviços.
Os nomes, são, mais uma vez enganadores. Poderíamos trocar todos nomes por outros que sejam mais próximo ao que a nossa aplicação faz, mas a estrutura do diagrama não é ambígua como acontecia com os diagramas da Arquitetura Clean ou em Cebola.
Embora, no seu cerne, todas estas arquiteturas tenham os mesmo propósito e as mesmas vantagens sobre uma arquitetura linear nem todas proveem a mesma clareza de implementação.
Variantes
Como apontado no livro do Robert C Martin as camadas podem ser mais ou menos conforme a necessidade. Em certos tipos de aplicação certas camadas mas internas podem não ser necessárias. Por exemplo, num sistema de ETL que só carrega, transforma e grava dados, não há propriamente um domínio. Nesse caso poderíamos ter algo assim:

E poderíamos pensar casos onde apenas as camadas externas seriam necessárias , ou casos em que mais camadas internas seriam necessárias. Na prática as 5 camadas que apresentamos são frequentemente suficientes, por razão que têm que ver com outras construções já abordadas no passado.
Conclusão
Tentei mostrar os detalhes de design das arquiteturas Clean, Onion e Hexagonal, focando a atenção naquilo que as torna semelhantes: a Regra de Dependência , e onde estão as lacunas que são tratadas em uma mas não na outra. A arquitetura Hexagonal nos dá as duas regras principais que precisamos, a arquitetura Onion nos diz como o cora da aplicação é estruturado e a arquitetura Clean nos prova como estes conceitos derivam de primeiros princípios
No fim, concluirmos que temos mesclar todas essas informações num padrão mais abstrato de Arquitetura Plana onde existem duas direções de decisão em vez de apenas uma presente nas arquiteturas lineares mais clássica.
No próximo artigo irei detalhas o conteúdo de cada camada em termos das classes que as habitam. Até lá.