No artigo anterior apresentei como um novo conceito de arquitetura emerge se analisarmos as arquiteturas Clean, Onion e Hexagonal em conjunto: a arquitetura plana.
Neste artigo irei mostrar em detalhes as classes em cada camada e como isso se relaciona a outros conceitos como DDD , CQRS e Micro Serviços.
Relembremos o diagrama base de qualquer arquitetura plana:
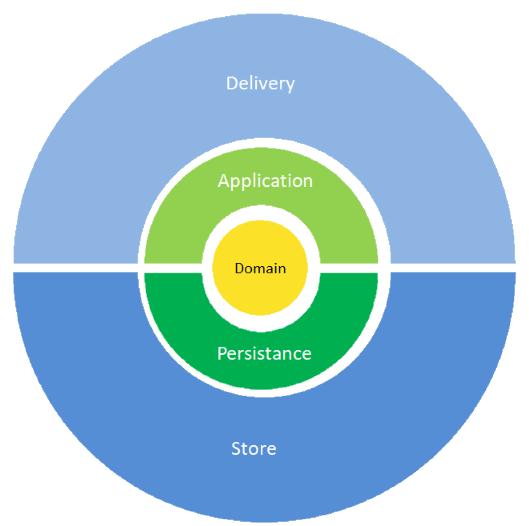
Vejamos agora o detalhe das classes principais e mais emblemáticas de cada camada.

Aqui estou usando um fluxo que começa com uma chamada REST a um RestController. Veremos mais à frente como seria em outros tipos de entrega.
O RestController, recebe dados em objetos. Normalmente algum tipo de framework é usado para fazer a conversão entre os dados dentro da requisição HTTP e o RestController. Estes objetos de dados são chamados aqui de Resource. Estes objetos vivem apenas na camada de delivery e nenhuma outra camada os pode usar. O RestController invoca um método em um ApplicationService. É importante que ele invoque apenas um método em um ApplicationService. Isto representa a chamada ao caso de uso. O RestController é, na linguagem da arquitetura hexagonal, um adaptador. Ele adapta o protocolo HTTP e a tecnologia do framework sendo usado para a chamada à aplicação. A Aplicação é o conjunto das camadas verdes e tudo o que está dentro delas, mas usamos o prefixo Application apenas para a parte verde claro, porque é onde as regras de aplicação ficam. A parte verde escuro tem mais que ver com persistência, então usamos nomes mais relacionados a persistência como Repository e DAO.
Repare que o RestController só tem conhecimento da interface do serviço da aplicação, mas essa interface tem métodos que recebem e retornam dados. Os objetos de dados próprios à camada verde claro são usados pela camada azul, portanto o RestController teria que converter os dados que recebeu em Resources para dados do modelo. Como isto é uma tarefa repetitiva, encapsulamos a conversão num objeto Converter.
O ApplicationService é implementado por uma classe OrchestrationApplicationService. Como podem ver eu não uso o sufixo Impl, mas, para ficar claro, o OrchestrationApplicationService é a implementação padrão da interface ApplicationService.
O OrchestrationApplicationService pode então orquestrar outros serviços, tanto outros serviços de aplicação como serviços de domino. No caso do exemplo existe um OtherApplicationService que é invocado. Mas repare que a implementação dele está de volta na camada de Delivery pois se trata de um integração de web services. A verdadeira lógica do OtherApplicationService existe realmente em outro sistema e o que estamos fazendo aqui é criar mais uma adaptador WebServiceAdaptor para mediar entre o serviço da aplicação e o serviço externo. Esta comunicação pode ser feita usando o protocolo que quisermos pois a única classe que tem que saber qual é, é o WebServiceAdaptor. Se mudarmos de tecnologia de comunicação – digamos, de SOAP para REST – apenas a implementação desse adaptador muda. Ou, melhor ainda, criaríamos uma outra implementação que usa o protocolo novo. O importante entender é que a interfaces OtherApplicationService não muda, e portanto nenhuma outra camada irá ser alterada se alterarmos o adaptador de web services.
Em algum momento o OrchestrationApplicationServiceterá que consultar as regras de negócio ou os dados de negocio. Para isso ele fará uma chamada a um, ou vários, DomainServices. Lembre-se que o OrchestrationApplicationService é livre de orquestrar diferentes serviços, tanto de aplicação como de domínio. Note, também, que o OrchestrationApplicationService apenas conhece a interface do serviço de domínio e não a sua implementação. Estamos seguindo à risca a Regra de Dependência.
A interface DomainService é implementada por um BusinessDomainService dentro do domínio. Não estamos representando aqui como o sistema determina qual implementação é usada pela aplicação, o que importa é que o fluxo continuará para o BusinessDomainService.
O BusinessDomainService por sua vez pode chamar outros serviços do domínio, outros tipos de objetos de domínio como validadores, por exemplo, e pode chamar métodos em entidades. Entidades essas que ele pode precisar obter de um repositório.
É importante pararmos um pouco aqui e vermos que todos os objetos da camada amarela de domínio correspondem a conceitos de DDD. Isto não significa que não podem haver outros tipos de objetos, mas que se existem, provavelmente são supérfluos. A representação não mostra os outros vários tipos de objetos de domínio que podemos ter ali, mas é importante lembrar alguns importantes como : Validator, Specification e DomainEvent. Mais sobre DomainEvent mais à frente.
A camada de domínio deve ser modelada totalmente conforme as regras de Domain Drive Design (DDD) e seguindo uma orientação a objetos mais pura. Sendo que a arquitetura plana isola completamente toda e qualquer classe no domínio, ele pode ser totalmente construido e testado independentemente de tudo o resto. Esta prática casa perfeitamente com as necessidade do DDD.
Há que reparar também que o OrchestrationApplicationService pode invocar diretamente repositórios do domínio. Isto por dois motivos:
- O
OrchestrationApplicationServiceirá precisar das entidades para enviar aos objetos deDomainService - O
DomainServicenão é um Façade do Repositório.
Esta separação ajuda também a separar canais de pesquisa (Query) que normalmente só precisam do Repositório e canais de comando (Command) que atuam sobre o estado da aplicação e implicam em pesquisa mas principalmente em atualização dos dados existentes no repositório. Isto nos ajudará a introduzir os conceitos de CQS e CQRS mais à frente.
O repositório é implementado recebendo e retornando os próprios objetos de entidade do domínio. Mas estes objetos podem ser bem complexos e não corresponder a uma estrutura ideal para persistência. O papel do repositório é realizar pesquisas e atualizações ao estado do sistema de formar compatível com o que o Domínio espera. Isto implica converter os dados existentes nos objetos Entity, para dados que possam ser persistíveis, removendo, por exemplo, coisas como referências cíclicas. O resultado é um conjunto de objetos de dados. Estes dados podem ser entendidos como as linhas de uma tabela ou as entradas de um dicionário conforme o tipo de persistência que usar. Contudo a real tecnologias de persistência apenas existe na próxima camada de Store.
No diagrama são apresentadas duas alternativas frequentemente usadas: um DataStore que segue uma modelagem que conhece as relações entre os objetos como qualquer ORM e uma abordagem mais clássica de DAO para quando as pesquisas ou os comandos são muito específicos ao banco de dados em uso. Por exemplo, se precisarmos usar um store procedure no banco de dados. O DataStore pode também ser implementado contra um banco de dado NoSQL ou uma outra interface pode ser usada pra isso, por exemplo, DocumentStore ( não mostrado no diagrama). O importante reter aqui é que o repositório não sabe sobre a tecnologias de persistência, mas ele pode saber que tipo de modelagem os dados têm : flat ( em tabelas) , outras formas como documento, grafo ou chave-valor (NoSQL), ou até nem saber e deixar o DAO se virar com isso.
As implementações na camada azul escura do Store são adaptadores de saída e, à semelhança do RestController e do WebServiceAdapter servem para mediar com o mundo externo.
Tecnologia e Frameworks
Apenas os objetos das camadas azuis, mais externas, podem depender de tecnologias e frameworks. Coisas como anotações só podem ser usadas nestas camada.
Tornar a aplicação (camadas verdes) independente de tecnologias especificas é objetivo primário das camadas azuis existirem. Desta forma a camada de aplicação pode ser testada sem precisar depender de frameworks externos. Ao mesmo tempo isto nos dá mais liberdade de mudar as tecnologias e frameworks quando vemos que eles não cumprem seu papel ou existem outros melhores. Às vezes essas mudanças são motivadas por causas externas ao sistema, como a mudança de SOAP para REST porque o serviço remoto foi atualizado ou mudar de SqlServer para PostgresQL por que a empresa decidiu poupar dinheiro em licenças.
Converters como um framework
Na prática usaremos os conversores a todo o momento. Eles têm que ser bastante reaproveitáveis e recorrentes.
Normalmente um conversor faz um conversão automática entre propriedades do mesmo nome, mas é bom que seja possível criar um conversor com lógicas mais complexas. Por outro lado conversores entre tipos fundamentais como String , int e double são sempre iguais.
Assim o ideal é construir um mini framework de conversão que resolva os casos mais comuns mas que permita extensão para os casos mais específicos. Isto poupara trabalho em futuros projetos.
Por outro lado, poderíamos pensar em usar um framework de mercado para essa tarefa. Isto tem prós e contras. O pró é que está pronto e é só usar. Muito provavelmente já foi usado por muitas pessoas e garantido por seus próprios testes. Por outro lado, o framework de mercado pode ter comportamentos ou necessitar de configurações que violam nossas regras. Por exemplo, é comum que este tipo de frameworks funcione através de anotações. Anotar um objeto Resource não tem problema por que estando na camada azul de adapters é perfeitamente lícito que dependa de frameworks. Mas, o mesmo não é verdade para objetos do modelo ou entities. Colocar anotações nestas classes seria uma violação das regras de independência que estamos tentando criar. Então, para usarmos frameworks de conversão, a configuração da conversão teria que acontecer sempre nas camadas azuis, por exemplo, usando uma API fluente de configuração. Se o framework não mantém protegida a independência das camadas mais internas, não é uma boa escolha e ficaremos melhor usando nosso próprio framework, que – claro está – não incorre nesses erros.
Este mesmo conceito pode ser aplicado a qualquer framework. Provavelmente será difícil usar JPA/Hibernate ou qualquer outro framework que não disponibilize formas não intrusivas de configuração
Ouvindo eventos do domínio
Umas das capacidades mais interessantes do domínio é capacidades dos serviços comunicarem usando eventos. Estes eventos de domínio – que são objetos imutáveis- são levantados por um serviço de domínio e enviados a um despacho central ( o DomainEventBus). Por outro lado, é possível registrar listeners junto a esse despacho central para receber os eventos. A implementação do despacho central apenas tem que distribuir os eventos pelos seus ouvintes
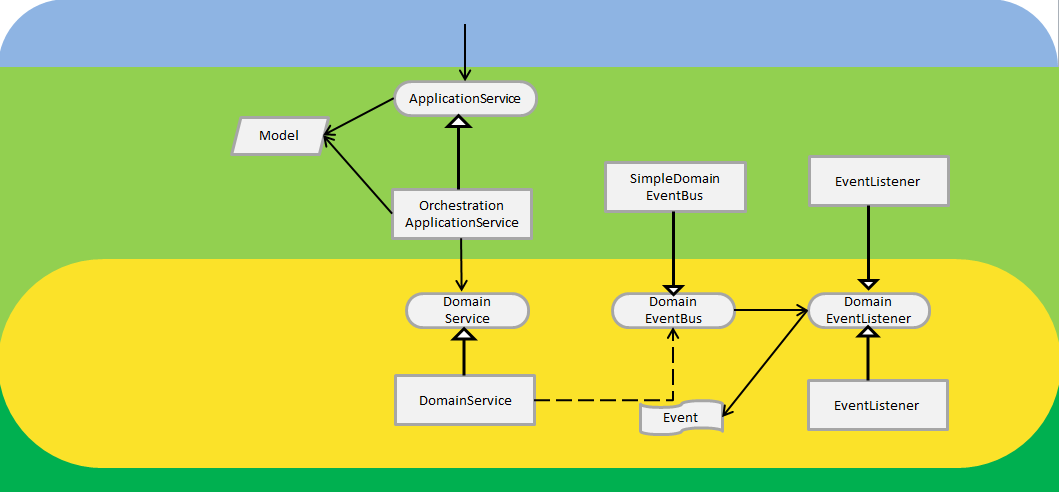
Podemos ver como uma arquitetura plana pode nos ajudar tanto a injetar a implementação de event bus que desejarmos – que pode ser o mesmo que usamos na camada de aplicação – tanto a criar listeners. Listeners pode ser criados tanto do lado do domino como do lado da aplicação. Isto seria impossível em uma arquitetura linear de camadas em pilha.
O lançamento de eventos permite que programemos ações quando algo acontece. Por exemplo enviar um email de boas-vindas quando um novo cliente se cadastra.
Micro serviços como comunicação entre serviços de aplicação
O conceito de micro serviços está na moda. Ainda não há um consenso quanto à definição do escopo de um micro serviço. Alguns dizem que tem que ser um função, alguns dizem que alguns métodos, alguns dizem que um contexto de domínio inteiro. A arquitetura plana pode ajudar.
Se pensarmos na camada de aplicação como a camada como aquela que orquestra é razoável pensarmos que ela pode invocar serviços de outras aplicações. Estas aplicações podem ser de terceiros – do governo, dos correios, etc. – ou da própria empresa.
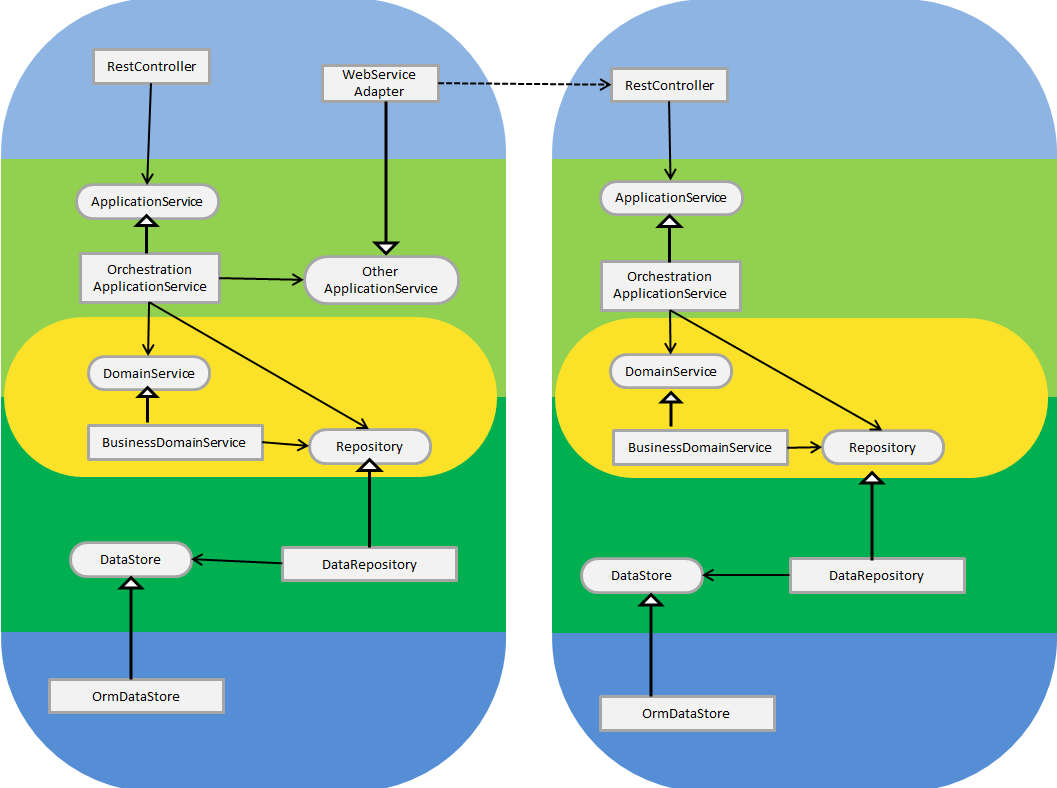
As camadas amarelas em cada sistemas podem ser :
- Contextos do mesmo domínio de um sistema maior. Neste sentido cada sistema isola os contextos de domínio um do outro, não apenas de forma lógica, mas também de forma física. Cada contexto pode ser implementado com a tecnologia que mais se adequa a ele de forma independente.
- Contexto de domínios diferentes mas compatíveis. Por exemplo, quando usando um sistema de terceiros existem conceitos em comum durante a comunicação mesmo que internamente o sistema externo use outros conceitos para trabalhar.
- Contextos de domínios diferentes e não compatíveis. Neste caso a camada de aplicação tem como objetivo adaptar e traduzir o uso de um domínio de forma a ser usado pelo sistema chamador. Este é o caso quando utilizamos um sistema legado, por exemplo.
Como vemos, não importa muito qual é a relação entre os domínios, a arquitetura plana dá suporte a este conceito de forma simples porque pode esconder um sistema inteiro atrás de um serviço de aplicação.
A forma como traduzir monolitos – que são sistemas cujos application services são todos implementados in loco – para micro serviços, em nada mais implica que implementar um ou mais application services em outros sistemas isolados.
CQS – Command Query Separation
Já vimos que o application service orquestra as chamadas a outros serviços, tanto de domínio como de aplicação e a repositórios. O padrão Comand Query Separation (CQS)[1][2] nos convida a garantir que só há dois tipos de métodos. Aqueles que apenas pesquisam dados, e aqueles que apenas modificam o estado do sistema. Necessário não confundir com o padrão CQRS ( command query responsability segregation) que visa outra coisa. Mais sobre as diferenças depois.
Em um sistema sem CQS teriamos um serviço de aplicação como este:
// java
public interface ProductApplicationService {
public Optional<Product> findBykey(Key<Product> key);
public List<Product> findAllActiveProducts();
public List<Product> findAllProductsWithStock();
public void deactivate(Product product);
public Product save (Product product);
}
Temos alguns métodos de pesquisa e alguns que modificam o estado. O CQS apenas nos sugere garantir que cada método só tem uma de duas responsabilidade : pesquisar ou modificar. Se aplicarmos este conceito obtemos isto:
// java
public interface ProductApplicationService {
public Optional<Product> findBykey(Key<Product> key);
public List<Product> findAllActiveProducts();
public List<Product> findAllProductsWithStock();
public void deactivate(Product product);
public void save (Product product);
}
Repare que o método save passou a ter retorno void. Isto é porque se há um retorno então significa que algum tipo de pesquisa foi feita, não queremos isso.
Os métodos de um Query Service apenas pesquisam dados sem nunca os modificar.Os métodos do Command Service apenas modificam o estado do sistema. Não têm retorno.
É importante notar que o CQS não ser trata de usar os padrões Command e Query Object e passar ambos para um mecanismo de interpretação. Não. O objetivo é bem mais simples e modesto, é apenas garantir que os métodos que modificam o sistema não fazem pesquisas. Não é necessário usar nenhum framework a mais para isto. É apenas uma simples decisão de design.
CQRS – Command Query Responsability Segregation
O Command Query Responsability Segregation – CQRS [1][2] se inspira no Principio CQS e nos convida a utilizar do Principio de Segregação de Interfaces (ISP – Interface Segregation Principle) e a separar fisicamente os métodos que apenas buscam algo (query) daqueles que mudam o estado da aplicação (command) , criando dois modelos separados. Podemos dizer que duas “sub-aplicações” . Então teríamos duas interfaces de Application Service:
// java
public interface ProductApplicationQueryService {
public Optional<Product> findBykey(Key<Product> key);
public List<Product> findAllActiveProducts();
public List<Product> findAllProductsWithStock();
}
public interface ProductApplicationCommandService {
public void deactivate(Product product);
public void save (Product product);
}
Eu usei os infixo Query e Command para distinguir os dois, mas outros infixos são possíveis como Read/Write ou Search/Modify, por exemplo. A palavra “Command” pode causar confusão aqui pois não estamos falando do padrão de design “Command”.
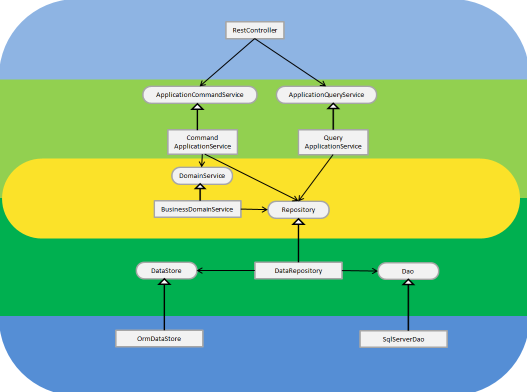
O CQRS implica em eventos sendo utilizados para que o modelo que escrita (Command Model) possa avisar o modelo que pesquisa (Query Model) de que é hora de atualizar a pesquisa. Desta forma este padrão é da família do MVC onde eventos também são trocados entre a model e a view quando os dados do model mudam, mas difere do MVC por que os eventos podem não ser explícitos ou não estar na mesma camada.
A forma mais comum de usar CQRS é entender cada parte como um canal. As modificações são enviadas para o serviço de Command que as enfileira e com isso atualiza o estado. O padrão Event Sourcing é muito usado neste estágio. Depois algum tipo de processo lê os eventos e realmente modifica o estado do sistema. Este estado pode ser obtido de novo reprocessando os eventos caso seja necessário. O processamento guarda os dados num banco de dados onde o modelo que query encontra a informação. Este mecanismo pode ser síncrono ou assíncrono conforme o processo de eventos seja síncrono ou assíncrono. Repare que o modelo de comando envia implicitamente um evento ao modelo de pesquisa pelo simples fato de gravar no banco de dados onde a pesquisa é feita. Não há realmente um mecanismo explicito de eventos, exceto os eventos de comando em si.
Uma vez que usamos o padrão CQS e separamos as interfaces dos serviços de aplicação é fácil, como vimos antes, isolar qualquer um deles em outra aplicação, caso necessário. Dai poderia-se usar o padrão CQRS adicionalmente. Nem todos os tipos de sistema beneficiam o uso de CQRS , mas todos podem beneficiar do uso de CQS.
Outros tipos de Delivery
Vemos no inicio um tipo de delivery simples baseado em REST. Um único objeto é responsável por adaptar a informação que vem do exterior para a informação que os application services entendem.
Uma outra forma possível seria um sistema MVC web baseado em HTML e processamento no server-side. Para sistemas MVC-web tradicionais o controler tem o mesmo papel do RestControler e não haveria muitas mudanças na forma como usar as classes na camada de delivery. Para arquiteturas que usam ASP.NET ou JSF um modelo baseado em MVP ajuda e é bastante usado. Nesse caso as classes da camada de delivery ficariam mais ou menos assim:
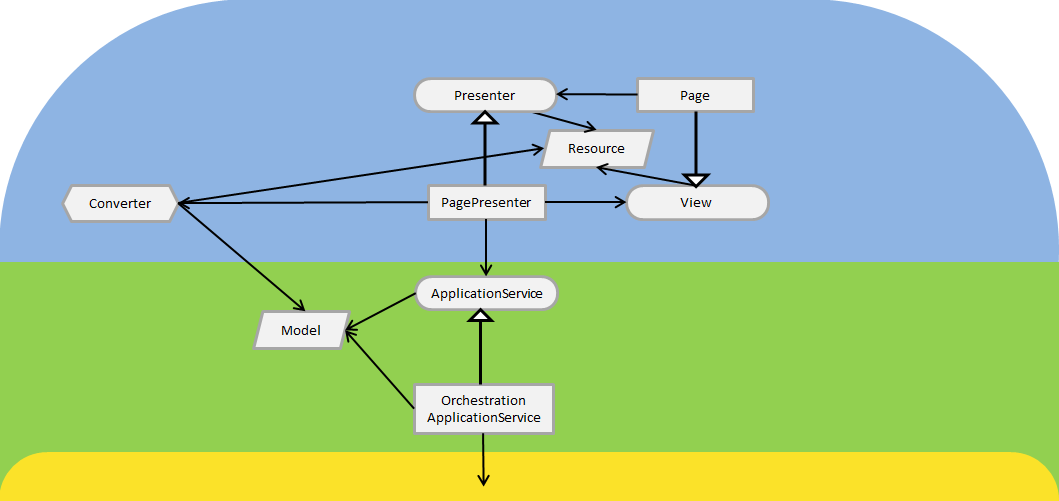
O objeto Page representa o vinculo tecnológico e é o real adaptador da camada. O padrão MVP permite que ao diferenciar entre View e Presenter as lógicas de controle seja desacopladas das lógicas de renderização, podendo mudar estas, sem mudar aquelas. Isto nos permite mudar a tecnologia de representação das páginas, sem ter que mudar a lógica sobre elas.
Conclusão
Vimos mais detalhes de como uma arquitetura plana se organiza no seu interior. Os padrões a serem usados em cada camadas são restritos a um pequeno conjunto. Não é necessário muito e não é necessário introduzir frameworks adicionais. Aliás queremos manter os frameworks o mais longe possível do core da aplicação.
A arquitetura plana funciona muito bem com arquitetura de micro serviços, CQS, CQRS e DDD. A arquitetura plana nos traz muito mais flexibilidade de design sem violarmos nenhuma regra de dependência ou de fluxo.
É importante entender que este plano , formado por este conjuntos de camadas é só a ponta do iceberg. Existem outros planos em profundidade. Estas camadas assentam em camadas de classes de bibliotecas de frameworks que não foram falado aqui, pois o objetivo da arquitetura plana é ser independente desses detalhes mais profundos. Mas em um sistema de verdade eles existem e não podemos esquece-los.
Mais sobre isso numa próxima oportunidade onde iremos abordar o conceito de arquitetura multi-dimensional.
[…] este artigo é reler esta tricotomia à luz da arquitetura multidimensional que abordei antes [5, 6, […]