Em post anteriores vimos como se caracteriza uma arquitetura plana a partir das arquiteturas Clean, Onion e Hexagonal. O objetivo de qualquer arquitetura plana é isolar o domínio do resto da aplicação e esta, por sua vez, de qualquer dependências tecnológica de bibliotecas e frameworks.
Chegamos num diagrama como este:
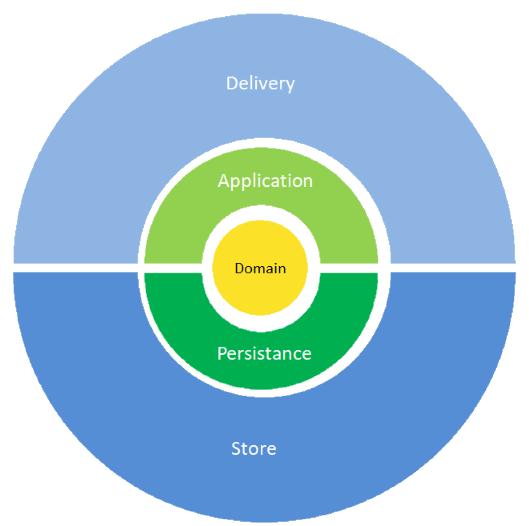
As camadas verde amarela não dependem de tecnologias e frameworks.
Vimos depois os detalhes das classes dentro de cada uma dessas camadas. Várias famílias de objetos têm lugares específicos dentro das camadas e ajudam a organizar as responsabilidades do código.
Agora vamos falar um pouco de como isto é só a ponta do iceberg e temos que pensar que ela se enquadra num modelo de andares como este:
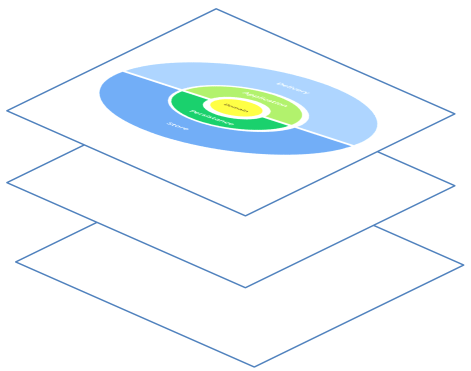
Por enquanto, não sabemos o que existe nos andares de baixo, mas sabemos que o primeiro andar isola a lógica de domínio e a lógica de aplicação de qualquer interferência tecnológica.
Descobrindo o que está por baixo
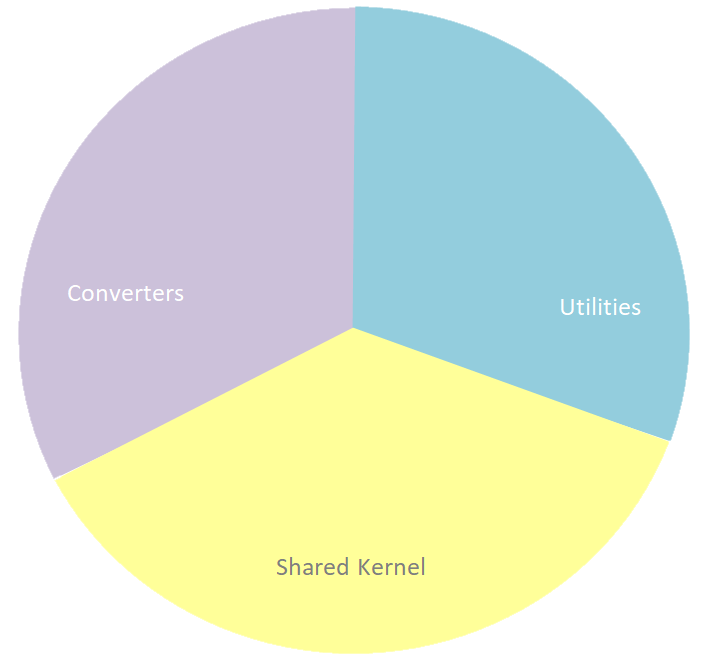
Na prática existem certas classes auxiliares que gostaríamos de compartilhar tanto entre diferentes sistemas, como entre diferentes camadas. Vimos o exemplo disso na classe Converter. Tanto a camada de entrega como a de aplicação precisavam de conversores para manter as camadas isoladas. Estes conversores implementam uma lógica recursiva em que os campos de um objeto são convertidos para os campos de outro objeto. Seria vantajoso se pudéssemos isolar essa lógica recursiva do propósito do conversor. Ou seja, não importa o quê estejamos convertendo, o algoritmo do processo de conversão seria sempre o mesmo.
Além de conversores podemos precisar de classes utilitárias que operam sobre tipos fundamentais como String ou BigDecimal e que são necessários à construção dos objetos de domínio ou de aplicação. Bibliotecas utilitárias como uma API de Datas e Horas ou uma que trabalhe com quantidades monetárias pode ser bem útil, dependendo da complexidade do domínio. Estas API têm uma reaproveitabilidade maior que as classes de domínio e de aplicação.
Por fim, se estamos usando Domain Driven Design (DDD) na nossa camada de domínio, é bem possível que esse domínio esteja dividido em contextos. Os contextos precisam – muitas vezes – comunicar entre si. Claro que não podemos usar classes de domínio para isso, então teremos que usar algum tipo de objeto desacoplado para transportar os dados entre os contextos do domínio. Por exemplo, como payload de um objeto de evento.O próprio objeto de evento é comum a vários contextos. Este conjunto de objetos de suporte ao domínio formam, segundo o DDD, o Shared Kernel (o núcleo compartilhado).
Na face da necessidade de todas estas outras classes, podemos então criar uma camada a mais onde colocar estas classes e partilhá-las com as camadas que precisam usá-las. O problema, é que, se criarmos essa camada junto das camadas que já temos vamos acabar violando as regras de dependência que construimos.
A solução, é então, pensar que estas novas camadas vivem em um outro, novo, andar:
O que nos leva ao seguinte diagrama:

Todas as camadas do andar de cima podem depender de camadas no andar de baixo. O inverso não é permitido. Já vimos que o uso de interfaces pode facilitar bastante a manter esta regra de dependência. Isto é especialmente útil para frameworks, como o de conversão. Interfaces e classes abstratas definidas no andar de baixo podem ser facilmente implementadas ou estendidas no andar de cima.

As camadas azuis dos andar de cima são as únicas que podem depender de frameworks e bibliotecas e conter anotações, por exemplo. Agora podemos ver onde poderiam estar estes frameworks, bibliotecas e anotações: em um andar inferior.
Neste andar inferior podemos ter qualquer tipo de biblioteca e framework, como Spring, Hibernate, Joda Time, Joda Money, etc.. É prudente aplicar aqui os mesmos princípios que aplicamos no andar de cima e isolar ao máximo estas bibliotecas e frameworks. Imagine um sistema que usava Joda Time em todas as classes de modelo e domínio. Obviamente isto simplificava muito a manipulação de datas e cálculos de tempo. Mas com o advento da biblioteca padrão de Date and Time API no Java 8, não há mais porque depender do Joda Time. É aqui que o Shared Kernel pode ajudar bastante. Modelando objetos próprios do Shared Kernel para as finalidades de representar datas e tempos e as operações necessárias ao domínio encapsulando o uso da verdadeira biblioteca, tornaria fácil remover a dependência do Joda Time e usar apenas a Date and Time API do Java 8. Isto reduz nossas dependências sem termos que modificar ou recompilar o andar de cima. Nem sempre isto é possível. Por exemplo, é muito difícil – para não dizer quase impossível – remover as dependências do Spring ou de qualquer outro framework que usemos para dar vida aos nossos controladores REST. Mas esses casos são exceção. A maior parte das API, e especialmente as que fazem parte do Shared Kernel e classes utilitárias é sempre possível esconder a verdadeira API. Isto nos leva a um refinamento no nosso segundo andar:

Repare que a Infraestrutura fica no centro, mantendo assim as regras de dependência que descobrimos e usamos no primeiro andar. As camadas azuis do primeiro andar podem depender desta camada de infraestrutura, assim como as outras camadas do segundo andar. Quanto mais esta infraestrutura isolar a verdadeira tecnologia como API de terceiros ou até as próprias API do SDK da linguagem, melhor. Isto torna o primeiro andar mais resiliente a mudanças tecnológicas ao longo do tempo.
O quanto mais a Infraestrutura isola as verdadeiras bibliotecas e frameworks mais longeva é a solução.
Sustentação
Todas as camadas e andares que vimos até agora assentam em uma base comum. Esta base sustenta todo o conjunto da edificação que andares que estamos construindo. Esta base é formada pela linguagem de programação e sua respectiva biblioteca padrão. A biblioteca padrão oferece certo tipos já implementados – como String, Integer ou Double – que formam os blocos padrão para construir os outros blocos. Muitas linguagens oferecem um pouco mais, como bibliotecas de coleções, bibliotecas para criptografia ou bibliotecas para acessar bancos de dados.
A linguagem em conjunto com a biblioteca padrão são a dependência última dos andares superiores. Contudo, muitas vezes precisamos de certos métodos que usamos recorrentemente, mas que não existem na biblioteca padrão. Nestas circunstâncias criamos nossas próprias bibliotecas ou recorremos a bibliotecas de terceiros como as bibliotecas da Apache, como o Apache Commons. Em linguagens que suportam extensões, como C#, e muito comum criarmos várias extensões para facilitar o trabalho e dar mais fluência ao código. Em linguagens que não suportam extensões é comum vermos o uso de métodos estáticos para resolver certo casos de uso mais frequentes.
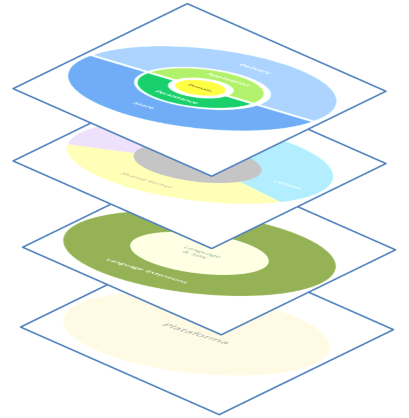
Seja que tipo de extensão você precisa ou se a implementa você mesmo ou usa uma de terceiros, o fato é que todas elas são escritas com base em uma certa linguagem. Isto nos leva a um diagrama como este:

Mantemos as mesmas regras de dependência de fora para dentro como nos outros andares. Atualizando o nosso modelo temos algo como isto :

As setas lembram a direção das dependências: de dentro para fora e de cima para baixo.
Olhando para o todo podemos ver como existem várias diferentes dimensões que nos ajudam a manter regras de dependência saudáveis, que por sua vez nos ajudam a manter o código organizado e a aumentar a vida útil do software. A linguagem nos dá uma base onde começar a construir o software. Podemos ter que estender a linguagem com mais bibliotecas dependendo do que precisamos e do que já vem incluído na biblioteca padrão. No andar mais de cima temos todas as lógicas de aplicação e negócio que são o cérebro e objetivo final do software: o software faz algo. No andar do meio temos um conjunto de classes que são mais direcionadas ao software que as classes básicas da linguagem, e que são compartilhadas entre diversas camadas dos andar superior. Este andar pode até ser compartilhado com outros primeiros andares.
Plataforma
Finalmente, a linguagem assenta em uma plataforma. Esta plataforma pode ser virtual como no caso de linguagens como Java, C# e Python em que as instruções são executadas em uma máquina virtual, ou pode ser uma plataforma física como linguagens como C++ e Rust cujas as instruções são executadas diretamente por CPU reais.
A escolha da plataforma é a primeira escolha que temos que fazer para poder montar nosso edifício de andares de arquitetura. Não poderemos mudar essa plataforma depois. Não sem ter muito trabalho e custos. Escolher a plataforma é onde assenta o maior risco e desafio. Se o seu alvo é uma plataforma especifica como seja um celular Android ou um celular iOS, não é preciso pensar muito. Ambos têm plataformas especificas. Mas se você visa os dois em simultâneo as coisas se complicam bastante. O mesmo para sistemas como Windows. Mac e Linux.
Além das diferentes plataformas, hoje em dias temos opção de diferentes linguagens em cada plataforma e até linguagens multiplataforma como Kotlin, Scala, Dart ou Ceylon. Estas linguagens normalmente se comunicam bem dentro da mesma plataforma com outras linguagens e com a linguagem nativa da plataforma. Isto nos dá mais margem de manobra caso queiramos construir nosso edifício arquitetural em mais de uma linguagem. Contudo, isso não é recomendado.
Podem existir casos onde misturar mais do que uma linguagem no seu edifício arquitetural seja uma boa aposta, mas isso tem que ser feito dentro das regras que abordamos – limitando o uso da linguagem a um conjunto restrito de camadas. Por exemplo, é muito comum termos que usar SQL para comunicar com o banco de dados, mas o uso essa linguagem é restrito à camada de Store. Da mesma forma, quando uma linguagem especial é usada para construir front ends o seu uso tem que ser limitado à camada de Delivery. Usar uma linguagem diferente para cada camada, embora possível torna a manutenção cada vez mais difícil porque que quem vai fazer a manutenção seja poliglota e fluente em todas essas linguagens. Há que usar com parcimônia e para os casos específicos onde a linguagem natural da plataforma não atende. Contudo com a evolução de vários padrões como Fluent Builder e a própria evolução das linguagens é cada vez menos necessário misturar linguagens.
Algumas pessoas defendem que a vantagem de usar micro serviços é poder construir diferentes nodos para formar o software. Cada nodo com seu edifício arquitetural e cada um com uma plataforma diferente. Isto pode funcionar em casos muito específicos onde a tecnologia de uma plataforma é mais eficiente de a que de outra. Mas não funciona no caso geral. Dito de outra forma; funciona quando os micro serviços representam serviços de aplicação, mas não quando representam serviços de domínio. Manter os contextos de domínio estritamente separados é equivalente a não existir um Shared Kernel e isso é equivalente a perde controle sobre as partes comuns dos contextos de domínio o que causa ruído na comunicação entre eles.
Arquitetura Multidimensional
Como vimos ao longo desta serie de artigos, a construção de um software passa pela definição de dependências entre as classes de uma forma que a manutenção de uma classe não implique em mudanças em outras. Ganhamos este isolamento estabelecendo camadas com responsabilidades especificas e regras rígidas de direção de dependência.
Considerando o que vimos até agora temos 3 direções de dependência a considerar :
De fora para dentro – as nossas camadas são concêntricas com as camadas mais exteriores dependendo das camadas mais interiores até uma camada central que é independente das demais.
Da entrada para a saída – as nossas camadas se dividem em duas regiões. Uma cuja responsabilidade é receber comandos externos e uma cuja responsabilidade é comandar outros software. Vimos como o conceito de portos e adaptadores nos ajuda a entender este fluxo.
De cima para baixo – a arquitetura plana não é suficiente na prática sendo necessário ter mais andares para incluir classes com responsabilidades importantes, mas que têm que ser compartilhadas pelas camadas originais. A dependência vertical vai até à plataforma escolhida para ser base do edifício arquitetural e está ligada ao conceito de que todas as camadas são construidas em cima de uma base comum.
Além da terceira dimensão
As 3 dimensões referidas são a base de uma boa arquitetura, mas não são as únicas. Na realidade existem outras dimensões mais complicadas de mostrar pictoricamente, mas que também desempenham um papel importante.
Aspectos
Aspecto é um conceito que conhecemos da Programação Orientada a Aspectos. A ideia é que conseguimos interceptar a chamada que um objeto faz e dessa forma expandir ou modificar o resultado da chamada. Os exemplos clássicos de razão para fazer isto são ações como log e auditoria, monitoramento como medição de performance e controle de transação.
Vários interceptores podem ser adicionados numa mesma chamada e realizar diferentes ações. Por outro lado, vários interceptores podem ser espalhados por diferentes chamadas em diferentes camadas.
O uso de aspectos se tornou fácil e bastante famoso mas se não for usado corretamente pode causar problemas. É necessário entender como ele pode respeitar as direções de dependência.
O uso de aspectos é principalmente relacionado com a questão de quando algo acontece. A ideia é intervir quando uma certa ação acontece e para isso colocamos uma forma de interceptar a chamada do método que representa que esse algo está acontecendo. Ora, à primeira vista isto pode parece simples e óbvio. Se interceptamos o método save de um repositório ou serviço pode saber quando algo foi salvo. Mas na prática não é bem assim. O método save de um serviço, por exemplo, pode realizar alguma validação que interrompe o processo e os dados não são realmente gravados.
Como regra os aspectos não podem conter lógica de negócios nem lógica da aplicação já que eles não pertencem nem à camada de aplicação nem à de domínio. Os aspectos vivem nas entrâncias entre as camadas:

Podemos ver em vermelho a região onde os aspectos vivem. Esta capacidade do aspectos de se intrometerem entre as camadas é o seu principal beneficio, mas é uma outra dimensão de dependência que temos que levar em consideração. Porque os aspectos vivem entre as camadas eles não podem depender de nenhuma outra camada do mesmo andar. Aspectos não podem depender da aplicação e muito menos do domínio.
O uso de aspectos é principalmente importante no tratamento de exceções. Cada camada tem suas exceções. Normalmente o tratamento final das exceções fica em algum interceptor na camada azul. Este interceptor é responsável por analisar a exceção e realizar algum tratamento. Por exemplo, mapear a exceção para um dos códigos de status do HTTP. Mas se a exceção é lançada da camada de domínio no centro, como a camada azul a pode tratar se não pode depender dessa camada ?
A solução é transformar as exceções entre as camada usando aspectos. Um aspecto pode ser incluído na chamada serviço ou repositório da camada de domínio. Conceitualmente este aspecto pertence e é construido na camada de aplicação, então ele tem acesso às exceções de domínio e de aplicação e mapear uma para a outra. Isto significa que o código de aplicação só recebe exceções de aplicação, mesmo quando chama objetos do domínio.
Este é um exemplo clássico do uso de aspectos numa arquitetura plana, mas existem outros. O importante é não colocar regras de negócio nestas classes.
Evolução temporal
Quando se constrói um sistema é muito comum os seus colegas, e sobre tudo seus chefes, lhe dizerem algo como “não se preocupa com isso agora, depois mudamos se for necessário” . Esta é a pior frase que pode ser dita em desenvolvimento de software e é a mais ouvida. Você não aceitaria isso de um empreiteiro se você perguntar onde vai ficar a cozinha e ele responder “não se preocupa com isso agora, depois mudamos se for necessário”. Certo?
Certas decisões têm que ser tomadas com antecedências e não podem ser mudadas depois. Se elas vão ser mudadas depois, há que isolar essa parte do sistema de forma que quando mudar não impacte o resto. Esse isolamento também tem que acontecer propositalmente. Então mesmo que não saibamos agora como vai ser no futuro temos que desenhar considerando que a forma como implementarmos agora será mudada depois. Temos que desenhar considerando o isolamento da parte que vai mudar. O isolamento entre o quê pode mudar e as suas opções futuras é necessário. Não podemos simplesmente ignorar esses fatos, fazer o software de qualquer forma e deixar para quem vier depois. Mas normalmente – e contra todas as regras do bom senso – é o que se faz.
Algumas vezes este isolamento advém do uso de certas ferramentas. Por exemplo, usando Hibernate é bem provável que não seja necessário mudar nenhum código se você migrar de usar um certo gerenciador de banco de dados para outro. Isolamento de banco de dados é meio que implícito se usar Hibernate. Mas nem sempre todas as funcionalidades são tão simples de compreender que será alvo de mudanças no futuro.
Não sei se você já foi alguma vez a pessoa que tem que dar manutenção nesses sistemas que têm muitos anos , ou, pior, ter que criar alguma nova funcionalidade. Eu já. E é até mesmo de sistemas que eu mesmo construir. Sistemas que existem há mais de 5 – 10 anos. Depois de tanto tempo você nem lembra direito qual era o modelo ou as regras. Você tem que ler o código. E o código tem que lhe dizer a regra. Quando as regras não estão isoladas e uma parte é feita na UI e outra no servidor e sabe-se lá onde mais, fica muito complicado de você voltar a entender o sistema. O que dirá, uma pessoas que nem nunca viu o sistema antes ?
A arquitetura multidimensional se preocupa também com essa dependência entre as camadas ao longo do tempo. As camadas têm de ser uma forma que seja fácil inclui mais camadas no meio , ou à volta. Tem que ser fácil trocar uma tecnologia por outra sem ter que mudar as regras ou mexer com os objetos que contém as regras. Esta foi a maior critica ao EJB 2 e que despertou ferramentas como o Spring e conceitos como DDD. Há que ter independência tecnológica das camadas de aplicação e de negócios. Enquanto a tecnologia evolui, essas camadas permanecem.
Não é economicamente viável você escrever uma aplicação nova a cada 3 ou 5 anos. Mas a tecnologia avança de uma forma que você será forçado a isso por fatores externos. A arquitetura multidimensional ajuda você a proteger o investimento na regras de domínio e de aplicação e permite que novos adaptadores sejam criados para ligar esse cerne do software a uma nova camada de delivery ou de storage.
Certas decisões são tomadas num certo ponto do tempo mas têm que ser afetadas tanto pelo histórico passado como pelo futuro. Normalmente o argumento agora seria algo como “não podemos prover o futuro” e de facto não podemos e não é isso que estamos pedindo. O próprio conceito de Orientação a Objetos mais básico é baseado em isolamento. Não é preciso muito para isolar algo, basta colocar todas as regras em uma única classe ou por detrás de um interface. Se as regras não estiverem espalhadas será muito mais fácil mudá-las depois. E não apenas isso, mas ter certeza que quando mudarmos a regra num certo ponto do código isso se reflete em todos os outros.
Conclusão
A Arquitetura Multidimensional não é nova. Arquitetura de Software sempre foi formada por diferentes facetas e dimensões. Mostrei em detalhe as 3 dimensões mais importantes e 2 dimensões extra que vale a pena ter em mente. Se conseguir focar sua atenção e dominar as 3 mais importantes já será um grande ganho e lhe dará insights para entender as outras.
Os detalhes de como o edifício arquitetural é dividido variam de autor para autor, o importante é entender que existem, pelo menos, 3 direções de dependência e uma plataforma que sustenta todo o edifício. Aqui tem outro exemplo.
As camadas em cada andar dependem do tipo de software sendo construido e talvez nem todas sejam necessárias para alguns projetos. O importante não é decorar as camadas mas entender o seu papel para depois entender se faz falta ou não no software que estamos construido.
Finalmente, é importante sublinhar que estes conceitos não se aplicam apenas a software de backend, mas a qualquer software em qualquer plataforma. Aqui tem um exemplo com Angular no frontend.